Zlatan Eevee
Jack of all trades and master of none.
-
Hadoop文件系统:HDFS
1 概述 2 架构 块 文件访问权限 3 文件读取 3.1 访问接口 3.2 客户端读取HDFS过程 4 文件写入 6 Fedoration 7 小文件解决方案 8 distcp 1 概述 HDFS应用场景:存储超大型流式处理数据(Terabytes和Petabytes级别)。 总的来说,HDFS的特点有这么几个: “write once, read many”,只...
-
Spark(一):介绍、初体验
1 介绍 2 安装 3 核心:RDD 4 基本架构 5 Quick start 5.1 spark shell 5.2 Self-Contained Applications 1 介绍 Spark是一个快速、通用的集群计算系统,提供JAVA/Scala/Python API,以及一系列的高级工具:Spark SQL/MLib/GrapyX/Spark Streaming. Spark的编程语言是scala,同样采用scala的还...
-
流式计算框架Storm介绍
1 背景:MR的问题 2 Storm的优势 3 编程模型 3.1 wordcount示例 4 基本架构 5 记录级容错 1 背景:MR的问题 启动时间长。多采用pull模型,没有JVM缓存池 调度开销大 中间数据写磁盘 storm的出现,可以比较好的解决上面的问题。 2 Storm的优势 实时计算、流式计算。水管不停的产生数据,流向中间的螺栓(处理逻辑)。 Storm出现之前的解决方法:消息队列,读取消息队列,更新数据...
-
笔记:DAG计算框架Tez
1 介绍 2 数据处理引擎 2.1 6种应用程序接口: 2.2 数据处理引擎 3 DAG编程模型 4 Tez带来的优化技术 5 总结 6 示例 1 介绍 目前的问题:如果作业由多个MR任务完成,则必然经过多次完整的Map–shuffer–Reduce,中间节点的数据多次写入HDFS,浪费IO读写。(可以将HDFS理解为多个任务之间的共享存储。)Tez的引入可以较小的代价的解决这一问题。 Tez采用了DAG(有向无环图)来组...
-
hadoop数据传输工具:Sqoop
1 简介 2 工具 2.1 直接查看数据库、表 2.2 将数据库导入import到hdfs 2.4 生成代码 1 简介 sqoop可以用来在hdfs和关系型数据(如mysql, Oracle, PostgreSQL)之间交换数据,也可以作为异构数据库之间同步使用。 sqoop通过JDBC(Java Data Base Connectivity,java数据库连接)与数据库交互,整合了Hive/HBase和oozie,核心是Map...
-
yarn(二):distributedShell和Unmanaged AM示例代码解析
一 示例执行 二 Client解析 1 创建Client对象 2 初始化 3 运行 三 Application Master解析 1 设置RM、NM消息的异步处理方法 2 向RM注册 3 计算需要的Container,向RM发起请求 4 RM分配Container给AM,AM启动任务 四 UnmanagedAM hadoop源码中,使用yarn的应用...
-
Ambari简介
1 介绍 2 架构详解 3 安装 3.1 配置ssh免认证登陆、hosts 3.2 下载官方yum源 4 验证 4.1 验证HDFS 4.2 验证spark on yarn 1 介绍 之前搭建hadoop平台(参加前一篇blog),采用的是手动安装、修改配置文件的方法。这样可以大致了解hadoop基本的部署过程,但是实际生产过程中不可能采用这种全手工的方法,后续还涉及到安装HBase/...
简单上两张图对比下管理界面: ambari: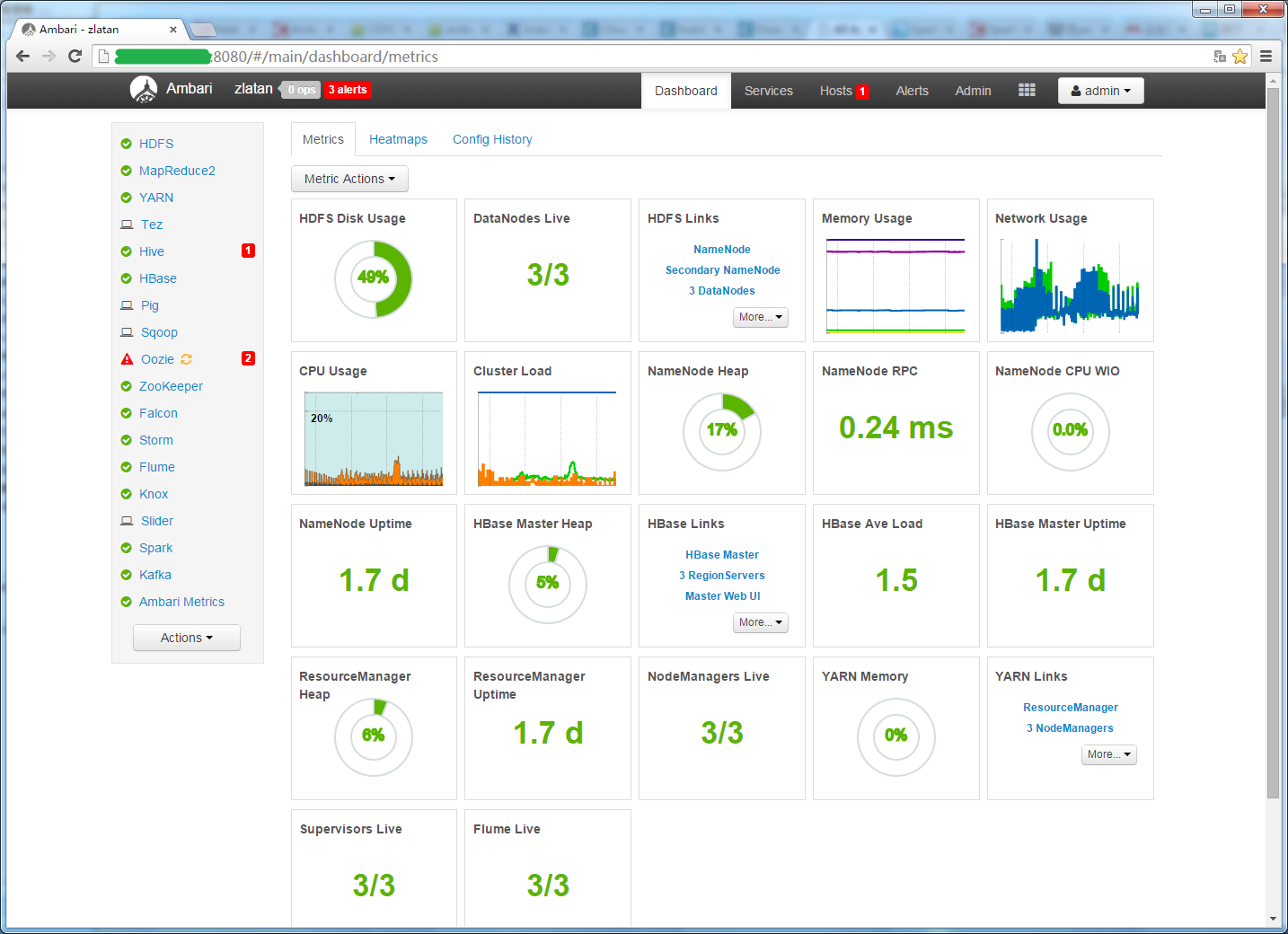 cloudera manager(官网上的图,后面等安装了CDH版本后再详细介绍吧 - -):
cloudera manager(官网上的图,后面等安装了CDH版本后再详细介绍吧 - -):

2 架构详解
暂时还没有深入了解,先挖个坑在这。 感兴趣的同学可以先看CSDN上的一篇文章,介绍的比较仔细。 简单来说,ambari利用了一些优秀的开源软件,做到了集群部署(puppet)、监控(Ganglia/nagios)、管理能力。
3 安装
我用的是3台阿里云的ECS,centos6.5系统,直接从hortonworks官方源拖的。ambari将安装做的已经非常好了,无奈受限于网络状况,安装过程中可能会出现失败的情况,retry就好了。吐槽一下ECS,不知道阿里的网络带宽是怎么限制的,实际使用起来有时效果比较糟糕,同一个地址下载可能一台几十KB,另一台可以达到3MB/s。 下面简单写一下安装过程吧,网上教程搜一下很多,这儿就只说一下坑。 建议直接参考官方的安装说明
3.1 配置ssh免认证登陆、hosts
请参考前一篇blog。
3.2 下载官方yum源
For Redhat/CentOS/Oracle: cd /etc/yum.repos.d/ wget <ambari-repo-url>坑:网上的教程多数还是基于1.x版本的,写blog的时候官方已经发布到了2.0.0(跳过了1.8/1.9)。 下载的repo url决定了使用的ambari版本,建议安装的时候去官网上找一下最新版本的repo url。 另,如果空间富裕的话,建议找一台虚机做一个官方源的镜像,后面安装会顺畅很多。 ####3.3 install, setup, and start ambari-server 步骤简单,
yum install ambari-server ambari-server setup ambari-server start安装完毕后访问
http://<ambari-server-host>:8080,有ambari的登陆界面,密码是admin/admin。
####3.4 安装hadoop/spark等服务 ambari提供了一个安装向导,按着来就行,具体可以参照chinaunix上的一篇blog,注意他用的是古老的1.4。 几个坑:
- 如果使用的是自己的镜像,需要在向导里就先修改为实际的镜像地址(需要关闭验证)。不要妄想这儿不改,等到安装各个服务的时候跑到
/etc/yum.repos.d/里去改,安装向导会强行覆盖的。 - 如果用的是比较老的比如1.4的版本,注册这一步可能会提示用的版本不匹配。
Cluster primary OS type is redhat6 and local OS type is centos5 Local OS is not compatible with cluster primary OS. Please perform manual bootstrap on this host.是安装脚本问题(AMBARI-4101),可以按patch修改
os_type_check.sh。我的办法是强行修改current_os与cluster一致。当然,直接上2.0吧,新版本已经改了这个bug了。- 要求输入各主机名列表时,务必使用FQDN格式(即
www.google.com之类),不能直接使用benzema/bale这种。 - 向导要求提供的是私钥,跟ssh免认证登陆不同(Q:为什么要私钥?)
- 如果安装各个服务的时候,失败的实在太多,可以先把包下载下来,手动安装。ambari retry对于已经安装过的只会检查。
- 如果不幸,你先安装了低版本的ambari,没关系,ambari是支持升级的,具体参考官方指导文档。如果不幸升级失败了,可以ambari-server reset全部复位掉。
- 想起来再补
4 验证
4.1 验证HDFS
登陆到HDFS的master控制台
[root@ty10 ~]# hadoop fs -ls / Found 8 items drwxrwxrwt - yarn hadoop 0 2015-04-29 15:42 /app-logs drwxr-xr-x - hdfs hdfs 0 2015-04-28 15:55 /apps drwxr-xr-x - hdfs hdfs 0 2015-04-28 15:50 /hdp ...4.2 验证spark on yarn
到安装spark client的主机上跑一下spark的示例应用:
spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster --num-executors 3 --driver-memory 2g --executor-memory 2g --executor-cores 1 lib/spark-examples*.jar 10yarn上查看application:
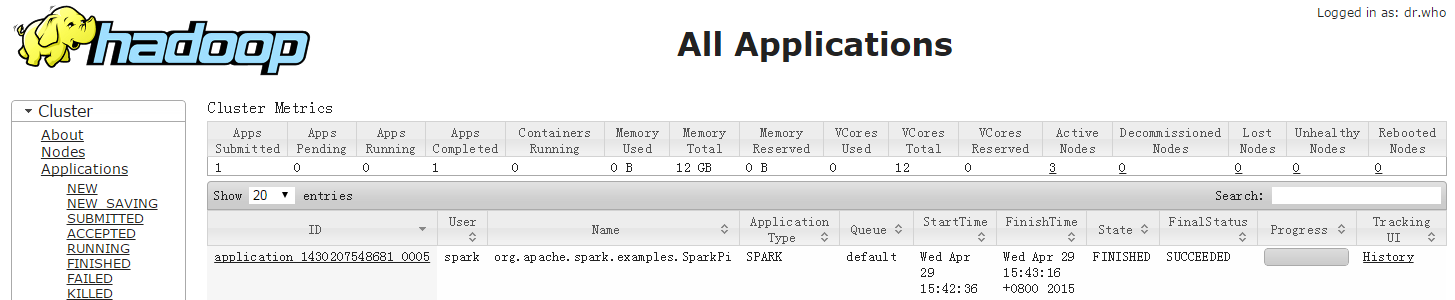
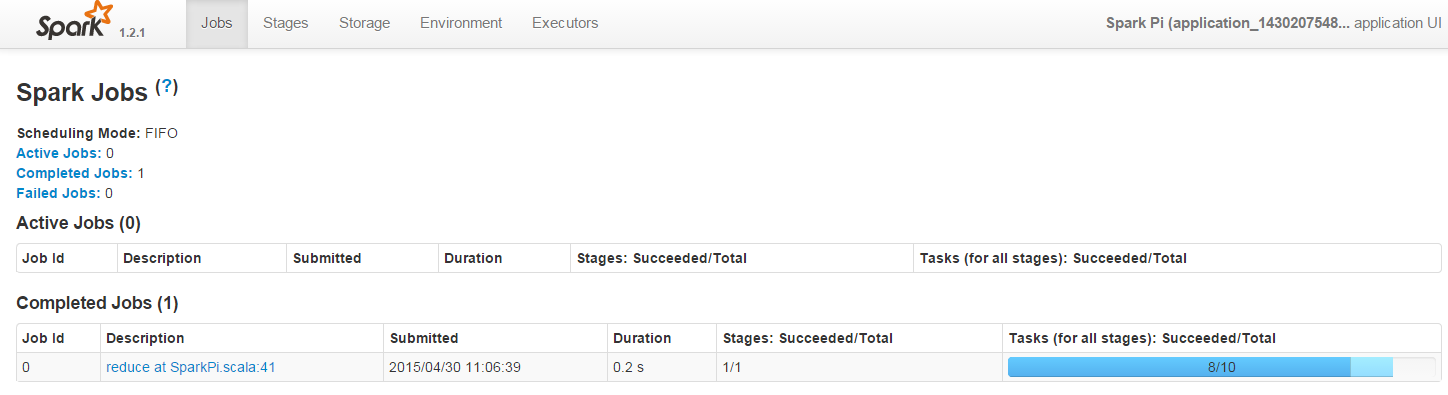
spark上查看任务:
-->
- 如果使用的是自己的镜像,需要在向导里就先修改为实际的镜像地址(需要关闭验证)。不要妄想这儿不改,等到安装各个服务的时候跑到
-
hadoop分布式环境搭建
1、 环境 2、 安装name node 2.1 安装centos6.5 2.1.1 配置网卡 2.1.2 配置iptables 2.1.3 配置本机ssh免密码登陆 2.1.3 修改hostname 2.2 安装JDK和maven 2.2.1 JDK 2.2.2 maven ...