流式计算框架Storm介绍
by 伊布
1 背景:MR的问题
- 启动时间长。多采用pull模型,没有JVM缓存池
- 调度开销大
- 中间数据写磁盘
storm的出现,可以比较好的解决上面的问题。
2 Storm的优势
实时计算、流式计算。水管不停的产生数据,流向中间的螺栓(处理逻辑)。
 Storm出现之前的解决方法:消息队列,读取消息队列,更新数据库,通知其他消息队列,存在缺点:自动化、健壮性、伸缩性。可以参考知乎的一个问答:
Storm出现之前的解决方法:消息队列,读取消息队列,更新数据库,通知其他消息队列,存在缺点:自动化、健壮性、伸缩性。可以参考知乎的一个问答:
问:实时处理系统(类似s4, storm)对比直接用MQ来做好处在哪里? 答:好处是它帮你做了: 1) 集群控制。2) 任务分配。3) 任务分发 4) 监控 等等。
总结Storm的优势:
- 分布式:只要修改并发任务数,就可以获得更好的分布式性能
- 运维简单
- 高度容错:模块无状态,随时可重启
- 无数据丢失:ack消息追踪记录
- 多语言编程接口:貌似还是以java为主
3 编程模型
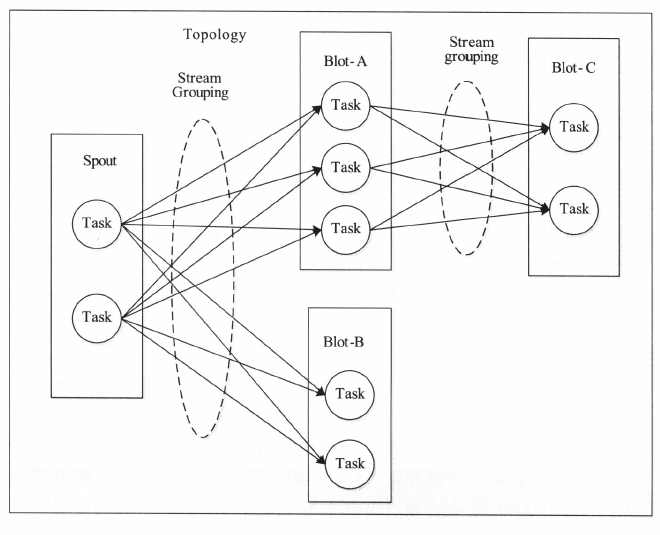
Tuple:数据表示模型,数据库中的一行记录,可以为integer、long,也可以自定义的序列化。
Stream:消息流。每个Tuple认为是一个消息,消息流就是Tuple队列。
Topology:应用程序处理逻辑,不会终止的MR作业。
Spout:消息源
Bolt:消息处理逻辑。多个Bolt之间有依赖关系,DAG组织。
Task:Spout和Bolt可以被并行化拆分为多个处理单元,每个单元为一个Task
Stream Grouping:消息分发策略,7种:随机、按字段、广播等。
如下图:
3.1 wordcount示例
还是以wordcount为例,代码在github上:点这里 wordcount分为1个Spout和2个Bolt,流程很简单: RandomSentenceSpout->SplitSentence->WordCount
创建TopologyBuilder,设置Spout、bolt,然后提交此拓扑。
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSentenceSpout(), 5); //5为并发消息源任务数
//8为Split并发任务数;shuffleGrouping指定了从Spout到SplitBolt的消息分发策略:随机
builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout");
//12为计数并发任务书;fieldsGrouping指定了从SplitBolt到WordCount Bolt的消息分发策略:按字段分组,保证同一单词分配到同一task
builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word"));
...
cluster.submitTopology("word-count", conf, builder.createTopology());
Spout的作用就是源源不断的产生数据,形象的描述就是一个“水龙头”。
示例代码中的Spout在open中先定义了一个随机数生成器,之后Storm框架会不断的调用nextTuple,每次随机从5条字符串中选取一条作为Tuple送到后面的Bolt。
public class RandomSentenceSpout extends BaseRichSpout {
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
_collector = collector;
_rand = new Random();
}
@Override
public void nextTuple() {
Utils.sleep(100);
String[] sentences = new String[]{ "the cow jumped over the moon", "an apple a day keeps the doctor away",
"four score and seven years ago", "snow white and the seven dwarfs", "i am at two with nature" };
String sentence = sentences[_rand.nextInt(sentences.length)]; //随机抽取一条字符串
_collector.emit(new Values(sentence));
}
Spolt丢出来的Tuple消息是一个多个单词组成的字符串,SplitBolt会先把它Split为多个单词
public static class SplitSentence extends ShellBolt implements IRichBolt {
public SplitSentence() { //调用python脚本来拆字符串
super("python", "splitsentence.py");
}
脚本将字符串Split以后再emit(发射)出去给下一个bolt。注意每次发射的是单个单词。
此脚本的路径是./multilang/resources/splitsentence.py
import storm
class SplitSentenceBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(" ")
for word in words:
storm.emit([word])
SplitSentenceBolt().run()
WordCount bolt将前面bolt发射出来的单词汇总起来,建立单词与词频的映射关系 由于采用了Field Grouping策略,WordCount bolt只要写入Map即可。
public static class WordCount extends BaseBasicBolt {
Map<String, Integer> counts = new HashMap<String, Integer>();
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getString(0);
Integer count = counts.get(word);
if (count == null)
count = 0;
count++;
counts.put(word, count); //写入Map表
collector.emit(new Values(word, count)); //继续向后发射
}
4 基本架构
Storm仍然为M/S架构,通过zookeeper通信。主要由下面几个组件构成:
- 控制节点:Nimbus,类似job tracker,分发代码、工作任务
- 工作节点:Supervisor,类似task tracker,根据需要启动关闭工作进程(Worker)
- Worker:负责执行具体任务的逻辑
- Task: Worker中每一个Spout/Bolt称为一个Task。0.8以后可以在一个线程中运行多个Spout/Bolt,这个线程称为Executor。
下图描述了一个任务的启动过程:

Numbus和SupervisorNumbus和Supervisor不直接交互,状态都保存在zookeeper上,故而重启不影响Storm。
Worker之间使用MQ传递消息。

5 记录级容错
所谓记录级,指的是一条tuple被所有应该走到的节点处理完毕。Storm的记录级容错使用了这样一个数学原理: A xor A = 0. A xor B…xor B xor A = 0,其中每一个操作数出现且仅出现两次。 Storm要求Spout发射消息时,将tuple id告知acker;要求Bolt发射消息时,将处理的tuple id和新生成的tuple id告知acker。这样所有节点处理完毕后,acker的异或结果为0。 如果acker在超时时间内检查不为0,则此记录失败。下面链接中淘宝的文章详细的说明了这一过程,不再赘述。
Subscribe via RSS