hadoop数据传输工具:Sqoop
by 伊布
1 简介
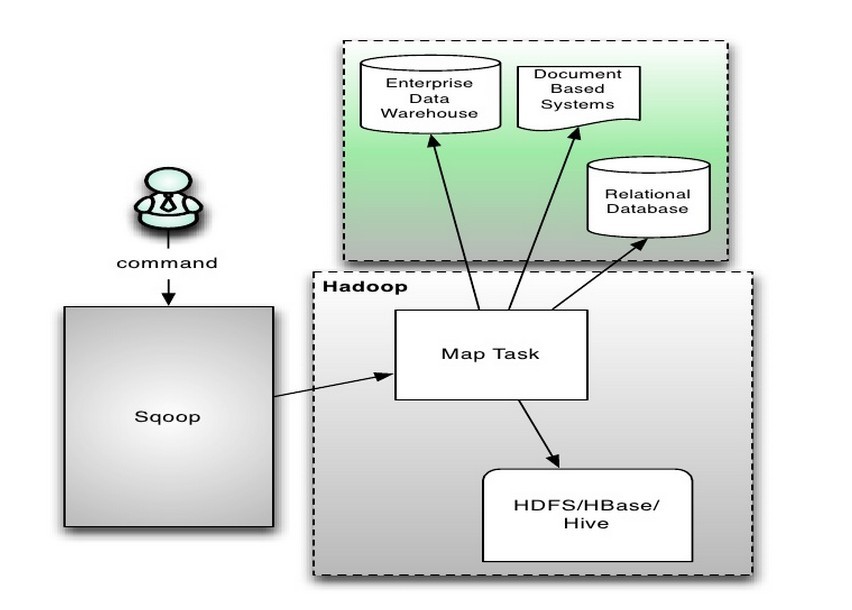
sqoop可以用来在hdfs和关系型数据(如mysql, Oracle, PostgreSQL)之间交换数据,也可以作为异构数据库之间同步使用。 sqoop通过JDBC(Java Data Base Connectivity,java数据库连接)与数据库交互,整合了Hive/HBase和oozie,核心是MapReduce。从下面的几个实验来看,应该只是用到了Map。
15/05/09 16:27:09 INFO mapreduce.Job: map 0% reduce 0%
15/05/09 16:27:16 INFO mapreduce.Job: map 75% reduce 0%
15/05/09 16:27:20 INFO mapreduce.Job: map 100% reduce 0%
15/05/09 16:27:20 INFO mapreduce.Job: Job job_1430310917645_0025 completed successfully
架构如下图:
 以下都是基于ambari安装环境下的sqoop1.4.5为例,如果你的sqoop执行时有下面这样的错误,可以
以下都是基于ambari安装环境下的sqoop1.4.5为例,如果你的sqoop执行时有下面这样的错误,可以yum install accumulo安装Accmulo。
Warning: /opt/cloudera/parcels/CDH-5.4.0-1.cdh5.4.0.p0.27/bin/../lib/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
2 工具
2.1 直接查看数据库、表
可以直接用sqoop查看mysql的库、表等。 下面的示例我们用sqoop跟mysql之间进行数据传输。安装mysql后默认会有3个database,我们这里的示例用test库。
$ mysql
mysql> use test
mysql> CREATE TABLE t1(id int not null, name char(20)); #在test库里创建一个表t1
Query OK, 0 rows affected (0.02 sec)
$ sqoop list-databases --connect jdbc:mysql://127.0.0.1/test --username root
15/05/09 14:49:39 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5.2.2.4.2-2
...
information_schema
mysql
test
$ sqoop list-tables --connect jdbc:mysql://127.0.0.1/test --username root
...
t1
2.2 将数据库导入import到hdfs
- 支持导入为文本文件、avro、sequence file。例如import时指定
--as-avrodatafile,写入到hdfs的文件就是avro格式的。 - 支持并发Map,通过-m参数指定
- 支持列选取(–column)、数据选取(–where)
- 支持append
- 数据可以导入到hive, hbase(–hive-import、–hbase-table)。实际还是先将数据导入到hdfs,然后再导入到hive/hbase。
下例将mysql的数据导出到hdfs的/tmp/bbb目录中。由于mysql没有设置primary key,所以使用了串行的-m 1,最终生成的文件也只有一个part-m-x。--columns可以指定多个列,比如我这里把2个columns都导出来了。
$ mysql
mysql> insert t1 values(100, "cat100");
mysql> insert t1 values(101, "cat101");
mysql> select * from t1;
+-----+--------+
| id | name |
+-----+--------+
| 100 | cat100 |
| 101 | cat101 |
+-----+--------+
$ sqoop import --append -m 1 --connect jdbc:mysql://127.0.0.1/test --username root --table t1 --target-dir /tmp/bbb --columns id,name
#以纯文件形式导入hdfs
$ current]$ hadoop fs -cat /tmp/bbb/part-m-00000
100,cat100
101,cat101
####2.3 将hdfs中的数据导出export到数据库
原理是根据用户指定的字段分隔符(默认是逗号)读入并解析数据,然后转换成insert/update语句导入数据到关系数据库。
如果你的源文件不是以逗号区分,导出时需要指定参数,否则会有这样的错误:Caused by: java.lang.RuntimeException: Can't parse input data: '100008 FLB100008 male'。字段分隔符参数的使用请参见下面的例子。
--fields-terminated-by <char> Sets the field separator character
需要指出,分隔符是严格按照char为分隔符,如果列之间有多个空格,像上面这样只给一个空格,就会将中间的空格作为一个列写入数据库。
$ mysql
#导出到mysql的表必须预先创建
mysql> CREATE TABLE exTable1(id int not null, name char(20), sex char(10));
#往hdfs上上传这么个文件:
$ hadoop fs -cat /tmp/bbb/newdata.txt
100001 FLB100001 male
100002 FLB100002 female
100003 FLB100003 male
100004 FLB100004 female
100005 FLB100005 female
100006 FLB100006 male
100007 FLB100007 female
100008 FLB100008 male
#导出到mysql
$ sqoop export --connect jdbc:mysql://127.0.0.1/test --username root --table exTable1 --export-dir /tmp/bbb --fields-terminated-by ' '
$ mysql
mysql> select * from exTable1;
+--------+-----------+--------+
| id | name | sex |
+--------+-----------+--------+
| 100001 | FLB100001 | male |
| 100002 | FLB100002 | female |
| 100003 | FLB100003 | male |
| 100006 | FLB100006 | male |
| 100007 | FLB100007 | female |
| 100004 | FLB100004 | female |
| 100005 | FLB100005 | female |
| 100008 | FLB100008 | male |
+--------+-----------+--------+
2.4 生成代码
可以使用codegen来生成针对此数据库的代码。
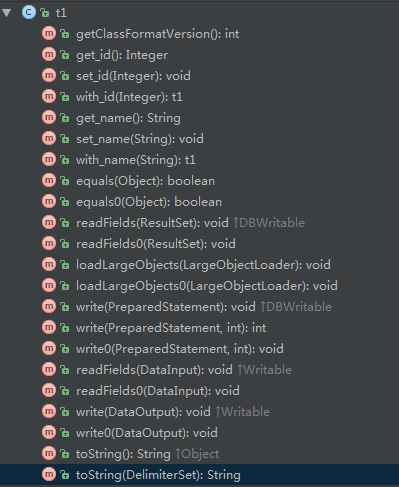
$ sqoop codegen --connect jdbc:mysql://127.0.0.1/test --username root --table t1
...
15/05/09 17:00:25 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hdfs/compile/a1c1551458745f7925db43a5df1485b9/t1.jar
t1.jar包同一目录下可以看到t1.java
public int write(PreparedStatement __dbStmt, int __off) throws SQLException {
JdbcWritableBridge.writeInteger(id, 1 + __off, 4, __dbStmt);
JdbcWritableBridge.writeString(name, 2 + __off, 1, __dbStmt);
return 2;
}
...
public Map<String, Object> getFieldMap() {
Map<String, Object> __sqoop$field_map = new TreeMap<String, Object>();
__sqoop$field_map.put("id", this.id);
__sqoop$field_map.put("name", this.name);
return __sqoop$field_map;
}
参考: 1、CSDN blog
Subscribe via RSS