hadoop分布式环境搭建
by 伊布
1、 环境
使用版本:centos6.5虚机安装在workstation 11上,使用hadoop2.6.0、jdk-7u15-linux-x64。本文介绍手工安装hadoop的方法,有关自动化部署(如ambari、cloudera management)的方法请见后续文章。
2、 安装name node
2.1 安装centos6.5
2.1.1 配置网卡
vmware默认安装即可,直接创建hadoop用户,建议配置2个网卡,如下。
安装时指定网卡eth0使用NAT模式,用来直接连接网络,后面编译的时候maven需要下载。
系统启动后,再增加一个网卡eth1,模式为桥接模式,选上复制物理网络连接状态。
如果你的PC跟我一样有多个网卡,可能桥接到的物理网卡不是你想要的,所以需要编辑为自己需要的网卡:
编辑->虚拟网络编辑器->更改设置,桥接模式使用的是vmnet0,选定后修改桥接到为准备要用的网卡。
配置完毕后,进到centos里ifconfig,可以看到新的网卡,我的环境里是叫做eth1(如果你用的是centos7以上的版本,可能叫做enp0s8之类奇怪的名字)。在我的环境里没有配置dhcp服务,需要设置为静态地址:
$ cd /etc/sysconfig/network-scripts/
$ vi ifcfg-eth1 #地址、掩码、MAC需要改为实际值
DEVICE="eth1"
BOOTPROTO="static"
IPADDR=192.168.5.29
NETMASK=255.255.0.0
HWADDR="00:0C:29:64:09:88"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
2.1.2 配置iptables
由于hadoop需要使用多个地址,而centos默认只开了几个端口,其他的都会被reject掉,所以需要改一下iptables。
我这里就粗暴的把iptables关闭了:service iptables stop。当然这样做有些风险,后面可以重新添加下iptables的规则。
2.1.3 配置本机ssh免密码登陆
hadoop启动、停止脚本是通过ssh来控制相关进程的,并且name node与data node通信时使用的是ssh,需要设置免密码登陆。
-
生成公钥、私钥
ssh-keygen -t rsa全部默认,执行完成后会在~/.ssh/生成2个文件:id_rsa(私钥)、id_rsa.pub(公钥)。尽量不要手动创建.ssh目录。 -
将公钥复制到相同目录下的authorized_keys文件中
cat id_rsa.pub >> authorized_keys
注意,一定要保证.ssh目录和authorized_keys的权限为600,否则免密码访问会失败。
配置完毕后切为root重启ssh服务器(service sshd restart),然后切回hadoop用户ssh localhost,可以看到不再需要密码。
2.1.3 修改hostname
分布式环境上要求各机器的名称是不一样的。我这里简单的把master节点命名为master,各slave节点命名为slave1、slave2、slave3。
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master
注意这里不要加.localdomain,否则dfs的web页面上查看datanodes时,会只能看到一个mailitciberia.com的节点,但实际上3个节点都已经注册OK了,fs的Configured Capacity也显示3个节点的总容量。
2.2 安装JDK和maven
2.2.1 JDK
下载jdk-7u15-linux-x64.tar.gz,解压到/opt目录下,配置环境变量:
$ vi /etc/bashrc #别写到/etc/profile,这个文件只对root生效(我也不知道为啥)
export JAVA_HOME=/opt/jdk1.7.0_15
export CLASSPATH=:$JAVA_HOME/lib.tools.jar
export PATH=$JAVA_HOME/bin:$PATH
2.2.2 maven
下载apache-maven-3.3.1-bin.tar.gz,解压到/opt目录下,配置环境变量:
export MAVEN_HOME=/opt/apache-maven-3.3.1
export PATH=$MAVEN_HOME/bin:$PATH
用户退出后重新登录,检查下java、mvn命令是不是都好用了。maven是为了后面编译代码用,如果只是部署hadoop,可以不安装。
2.3 安装hadoop
下载hadoop二进制版本hadoop-2.6.0.tar.gz,解压到/opt目录下。
配置文件基本都在/opt/hadoop-2.6.0/etc/hadoop里。
2.3.1 设置环境变量
只需要配置JAVA_HOME。前面已经在bash里设置了,这里不需要再修改。 涉及到的文件:hadoop-env.sh、yarn-env.sh
# The java implementation to use.
export JAVA_HOME=${JAVA_HOME}
2.3.2 设置mapred-site.xml
设置mapred使用YARN资源框架
$ cp mapred-site.xml.template mapred-site.xml
$ vi mapred-site.xml
<configuration>
<property> #增加此property
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.3.3 修改mapred-site.xml
设置fs使用hdfs,设置hadoop临时文件存放地址(这里设置为hadoop用户目录下的tmp),并创建该目录tmp。
$ vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<final>true</final>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>
2.3.4 配置hdfs-site.xml
设置hdfs的name、data节点使用的目录,并创建;设置hdfs的数据块副本个数为3,即一份数据块存3份。 需要注意,如果自己搭的环境里节点数不到3个,这里要设置为实际的个数。
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-2.6.0/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-2.6.0/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
2.3.5 配置yarn-site.xml
为了运行MR,需要让YARN的各Node Manager启动的时候加载shuffle server,Reduce Task通过该server从各个Node Manager上获取Map Task的中间结果。 有的资料还配置了YARN Resource各功能的监听端口,这儿我们用默认的即可。
上面这句话是错误的!!必须要配置,否则slaves找不到要连接的resource manager。
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.5.29:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.5.29:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.5.29:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.5.29:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.5.29:8088</value>
</property>
</configuration>
2.3.6 配置slave
需要设置slaves的域名或者地址。这儿先用地址。
192.168.5.101
192.168.5.102
192.168.5.103
3、 安装data node
说明:hadoop的分布式主要体现在hdfs上,name node下面管理了多个data node,data node可以有比较好的横向扩展性; 对yarn来说,也是存在resource manager下面管理多个node manager的情景,也是分布式。 由于这里用的是workstation,没有ESXi那种比较高级的功能,可以先把虚拟机关闭,然后拷贝出来一份,启动的时候选择“复制”。
启动后,新的node还需要再做下面几件事: 1 修改eth1配置中的IP地址和MAC地址 2 配置本机免密码登陆 3 修改hostname 另,集群环境上,master访问各slave节点也需要ssh免密码登陆。 配置master到slave免密码登陆的方法有很多,本质上就是把master的~/.ssh/authorized_keys里的public key添加到slaves的同一个文件里。我这里是直接2个窗口拷贝粘贴了。 配置后,从master访问slave也不再需要密码
4、启动hadoop
hadoop的操作只需要在master上操作,master会ssh到各slaves上去启动对应的进程。
4.1 启动hdfs
启动前需要先format:
$ ./bin/hdfs namenode -format
之后分别启动hdfs和yarn:
./sbin/start-dfs.sh
./sbin/start-yarn.sh
jps命令查看hdfs和yarn在master、slaves上都启动了哪些应用:
[hadoop@master hadoop-2.6.0]$ jps
7244 NameNode #hdfs
7590 ResourceManager #yarn
7942 Jps
7429 SecondaryNameNode #hdfs
---
[hadoop@slave1 hadoop]$ jps
3929 NodeManager #yarn
3836 DataNode #hdfs
4111 Jps
简单操作一下hdfs: $ ./bin/hadoop fs -mkdir /test $ ./bin/hadoop fs -ls / $ bin/hadoop fs -put $ ./bin/hadoop fs -ls /test
web访问: http://master:8088 查看yarn所有的slave节点: ![yarn slave]](/assets/qiniu/yarn_nodes.png)
http://master:50070
查看hdfs所有的slave节点:
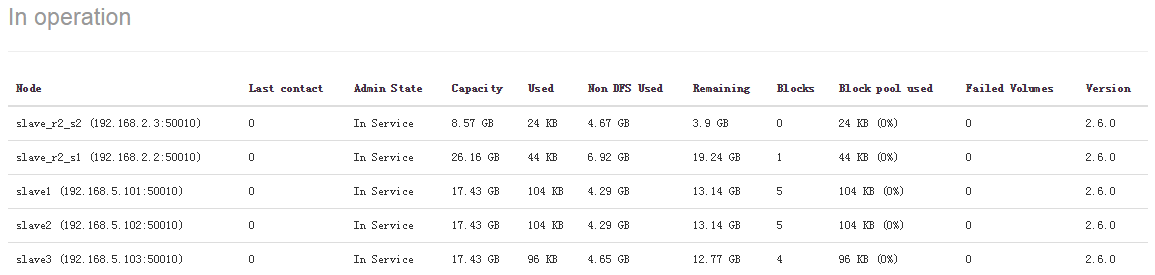
5、已有环境上新增一个slave节点
slave
1、打包master的/opt下所有文件,拷贝到新的slave节点下的/opt解压; 2、修改slave节点的/etc/sysconfig/networking中的hostname,重启 3、修改slave节点的/etc/hosts,添加
192.168.2.2 slave_r2_s1
192.168.5.29 master
4、配置ssh本地、远程免密码登陆 5、检查hdfs的data目录下是否为空,若否,则清空 6、创建tmp目录,如/home/hadoop/tmp。
master 1、修改master节点的/etc/hosts,添加新增的slave节点 2、修改master节点的$hadoop/etc/hadoop/slaves,添加新增的slave节点地址
6、已有环境上新增一个master节点
todo..
Subscribe via RSS