笔记:DAG计算框架Tez
by 伊布
1 介绍
目前的问题:如果作业由多个MR任务完成,则必然经过多次完整的Map–shuffer–Reduce,中间节点的数据多次写入HDFS,浪费IO读写。(可以将HDFS理解为多个任务之间的共享存储。)Tez的引入可以较小的代价的解决这一问题。
Tez采用了DAG(有向无环图)来组织MR任务。
核心思想:将Map任务和Reduce任务进一步拆分,Map任务拆分为Input-Processor-Sort-Merge-Output,Reduce任务拆分为Input-Shuffer-Sort-Merge-Process-output,Tez将若干小任务灵活重组,形成一个大的DAG作业。
Tez与oozie不同:oozie只能以MR任务为整体来管理、组织,本质上仍然是多个MR任务的执行,不能解决上面提到的多个任务之间硬盘IO冗余的问题。
Tez只是一个Client,部署很方便。
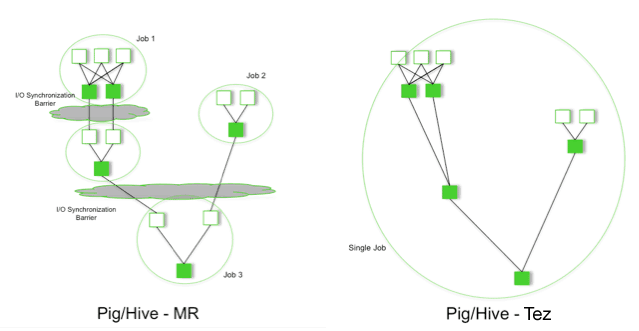
目前Hive使用了Tez(Hive是一个将用户的SQL请求翻译为MR任务,最终查询HDFS的工具)。下图对一个典型的join动作的两种方案做了对比。
2 数据处理引擎
2.1 6种应用程序接口:
- Input:解析输入数据,输出key/value
- Output:将key/value写入到HDFS
- Parititioner:数据分片
- Processor:计算单元抽象
- Task:Input->Processor->Output
2.2 数据处理引擎
略。
3 DAG编程模型
Tez通过有向无环图组织任务。一个DAG由若干Vertex(顶点,即处理逻辑,例如Map/Reduce)和连接Vertex的Edge(定义了Vertex之间的通信方式,例如Shuffle)组成。 以Tez的wordcount中的createDAG为例:
//定义2个Vertex
Vertex tokenizerVertex = Vertex.create(TOKENIZER, ProcessorDescriptor.create(
TokenProcessor.class.getName())).addDataSource(INPUT, dataSource);
//TokenProcessor为Vertex的处理逻辑
Vertex summationVertex = Vertex.create(SUMMATION,
ProcessorDescriptor.create(SumProcessor.class.getName()), numPartitions)
.addDataSink(OUTPUT, dataSink);
//SumProcessor为Vertex的处理逻辑
DAG dag = DAG.create("WordCount");
dag.addVertex(tokenizerVertex) //DAG
.addVertex(summationVertex)
.addEdge( //定义连接token和summation的Edge
Edge.create(tokenizerVertex, summationVertex, edgeConf.createDefaultEdgeProperty()));
上面定义的两个Processor可以分别类比Map Task和Reduce Task,定义的Edge可以类比Shuffle。
4 Tez带来的优化技术
1 Application Master Pool 初始化AM池。Tez先将作业提交到AMPoolServer服务上。AMPoolServer服务启动时就申请多个AM,Tez提交作业会优先使用缓冲池资源。 2 Container Pool AM启动时会预先申请多个Container。 3 Container重用
5 总结
相对oozie组织MR任务的方案,Tez带来3个提升:
- 避免了中间结果读写HDFS,减少磁盘+网络的开销
- Map结果数据量较小时可以写入内存(MPv1版本,Map的结果必须写入硬盘)
- 减少作业启动时间(AM池、Container池)
2.x的hadoop将Hive新版本将Tez引入作为自己的数据处理引擎,号称性能提升极大。 相对于Tez,Spark引入了RDD(弹性分布式数据集),使得频繁使用的数据集可以做到不同任务之间重用和共享,更优越一些。
6 示例
Ambari把hadoop安装到了/usr/hdp。
$ cd /usr/hdp/current/tez-client/
$ su hdfs
$ hadoop fs -ls /tmp
-rw-r--r-- 3 hdfs hdfs 1974 2015-04-29 20:38 /tmp/ida50a5665_date382915
-rw-r--r-- 3 hdfs hdfs 1974 2015-04-30 13:59 /tmp/ida50a5665_date593015
$ hadoop jar tez-examples-0.5.2.2.2.4.2-2.jar wordcount /tmp/ida50a5665_date382915 /tmp/aaa
15/05/09 10:06:21 INFO client.RMProxy: Connecting to ResourceManager at ronaldo7.ieevee.com/10.165.101.86:8050
15/05/09 10:06:22 INFO client.TezClient: Submitting DAG application with id: application_1430310917645_0011
15/05/09 10:06:23 INFO client.TezClient: Submitting DAG to YARN, applicationId=application_1430310917645_0011, dagName=WordCount
#向YARN提交DAG任务。DAG作为AM。
15/05/09 10:06:23 INFO impl.YarnClientImpl: Submitted application application_1430310917645_0011
15/05/09 10:06:23 INFO client.RMProxy: Connecting to ResourceManager at ronaldo7.ieevee.com/10.165.101.86:8050
15/05/09 10:06:23 INFO client.DAGClientImpl: Waiting for DAG to start running
15/05/09 10:06:28 INFO client.DAGClientImpl: DAG initialized: CurrentState=Running
#DAG开始运行,一共2个task
15/05/09 10:06:28 INFO client.DAGClientImpl: DAG: State: RUNNING Progress: 0% TotalTasks: 2 Succeeded: 0 Running: 0 Failed: 0 Killed: 0
15/05/09 10:06:28 INFO client.DAGClientImpl: VertexStatus: VertexName: Tokenizer Progress: 0% TotalTasks: 1 Succeeded: 0 Running: 0 Failed: 0 Killed: 0
15/05/09 10:06:28 INFO client.DAGClientImpl: VertexStatus: VertexName: Summation Progress: 0% TotalTasks: 1 Succeeded: 0 Running: 0 Failed: 0 Killed: 0
#先运行Tokenizer(Vertex)
15/05/09 10:06:32 INFO client.DAGClientImpl: DAG: State: RUNNING Progress: 50% TotalTasks: 2 Succeeded: 1 Running: 1 Failed: 0 Killed: 0
15/05/09 10:06:32 INFO client.DAGClientImpl: VertexStatus: VertexName: Tokenizer Progress: 100% TotalTasks: 1 Succeeded: 1 Running: 0 Failed: 0 Killed: 0
15/05/09 10:06:32 INFO client.DAGClientImpl: VertexStatus: VertexName: Summation Progress: 0% TotalTasks: 1 Succeeded: 0 Running: 1 Failed: 0 Killed: 0
#再运行Summation(Vertex)
15/05/09 10:06:32 INFO client.DAGClientImpl: DAG: State: SUCCEEDED Progress: 100% TotalTasks: 2 Succeeded: 2 Running: 0 Failed: 0 Killed: 0
15/05/09 10:06:32 INFO client.DAGClientImpl: VertexStatus: VertexName: Tokenizer Progress: 100% TotalTasks: 1 Succeeded: 1 Running: 0 Failed: 0 Killed: 0
15/05/09 10:06:32 INFO client.DAGClientImpl: VertexStatus: VertexName: Summation Progress: 100% TotalTasks: 1 Succeeded: 1 Running: 0 Failed: 0 Killed: 0
15/05/09 10:06:32 INFO client.DAGClientImpl: DAG completed. FinalState=SUCCEEDED
示例代码将结果写到了两个文件中:
$ hadoop fs -ls /tmp/aaa/
Found 3 items
-rw-r--r-- 3 hdfs hdfs 0 2015-05-09 09:35 /tmp/aaa/_SUCCESS
-rw-r--r-- 3 hdfs hdfs 2090 2015-05-08 14:44 /tmp/aaa/part-r-00000
-rw-r--r-- 3 hdfs hdfs 2090 2015-05-09 09:35 /tmp/aaa/part-v001-o000-00000
$ hadoop fs -cat /tmp/aaa/part-v001-o000-00000
Daemon:/:/sbin/nologin 1
HTTPFS:/var/run/hadoop/httpfs:/bin/bash 1
SSH:/var/empty/sshd:/sbin/nologin 1
...
参考:
Subscribe via RSS