代码解析Linux系统调用
by 伊布
Linux用户态进程,在使用一些内核功能的时候,是通过系统调用来完成的。本文会以一个bind动作为例,从代码上来理解整个系统调用的过程。注意kernel版本是v4.11,不同版本具体实现略有不同。
用户态是如何陷入到内核态的
以下面这个man bind的示例开始。
#include <sys/socket.h>
#include <sys/un.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#define MY_SOCK_PATH "/somepath"
#define LISTEN_BACKLOG 50
#define handle_error(msg) \
do { perror(msg); exit(EXIT_FAILURE); } while (0)
int
main(int argc, char *argv[])
{
int sfd, cfd;
struct sockaddr_un my_addr, peer_addr;
socklen_t peer_addr_size;
sfd = socket(AF_UNIX, SOCK_STREAM, 0);
if (sfd == -1)
handle_error("socket");
memset(&my_addr, 0, sizeof(struct sockaddr_un));
/* Clear structure */
my_addr.sun_family = AF_UNIX;
strncpy(my_addr.sun_path, MY_SOCK_PATH,
sizeof(my_addr.sun_path) - 1);
if (bind(sfd, (struct sockaddr *) &my_addr,
sizeof(struct sockaddr_un)) == -1)
handle_error("bind");
if (listen(sfd, LISTEN_BACKLOG) == -1)
handle_error("listen");
用户态调用了bind函数,其声明在<sys/socket.h>。
/* Give the socket FD the local address ADDR (which is LEN bytes long). */
extern int bind (int __fd, __CONST_SOCKADDR_ARG __addr, socklen_t __len)
__THROW;
用户态进程只要调用bind函数就可以了,具体bind函数的实现是由glibc提供的,其定义在glibc-2.23/sysdeps/unix/sysv/linux/bind.c。
int
__bind (int fd, __CONST_SOCKADDR_ARG addr, socklen_t len)
{
#ifdef __ASSUME_BIND_SYSCALL
return INLINE_SYSCALL (bind, 3, fd, addr.__sockaddr__, len);
#else
return SOCKETCALL (bind, fd, addr.__sockaddr__, len, 0, 0, 0);
#endif
}
weak_alias (__bind, bind)
从4.3版本内核开始,bind会直接走socketcalls。所以上述bind走INLINE_SYSCALL。
/* Direct socketcalls available with kernel 4.3. */
#if __LINUX_KERNEL_VERSION >= 0x040300
# define __ASSUME_RECVMMSG_SYSCALL 1
# define __ASSUME_SENDMMSG_SYSCALL 1
# define __ASSUME_SOCKET_SYSCALL 1
# define __ASSUME_SOCKETPAIR_SYSCALL 1
# define __ASSUME_BIND_SYSCALL 1
INLINE_SYSCALL定义在glibc-2.23/sysdeps/unix/sysv/linux/x86_64/sysdep.h
# define INTERNAL_SYSCALL_NCS(name, err, nr, args...) \
({ \
unsigned long int resultvar; \
LOAD_ARGS_##nr (args) \
LOAD_REGS_##nr \
asm volatile ( \
"syscall\n\t" \
: "=a" (resultvar) \
: "0" (name) ASM_ARGS_##nr : "memory", REGISTERS_CLOBBERED_BY_SYSCALL); \
(long int) resultvar; })
# undef INTERNAL_SYSCALL
# define INTERNAL_SYSCALL(name, err, nr, args...) \
INTERNAL_SYSCALL_NCS (__NR_##name, err, nr, ##args)
# undef INLINE_SYSCALL
# define INLINE_SYSCALL(name, nr, args...) \
({ \
unsigned long int resultvar = INTERNAL_SYSCALL (name, , nr, args); \
if (__glibc_unlikely (INTERNAL_SYSCALL_ERROR_P (resultvar, ))) \
{ \
__set_errno (INTERNAL_SYSCALL_ERRNO (resultvar, )); \
resultvar = (unsigned long int) -1; \
} \
(long int) resultvar; })
在syscall之前先将参数传入寄存器。然后x86-64使用syscall指令陷入内核(跟x86使用0x80中断去陷入内核不一样)。返回值在eax寄存器中,通常0表示成功。
syscall的name为__NR_##name,在本例中即为__NR_bind。其定义在/usr/include/asm/unistd_64.h中。
#define __NR_bind 49
#define __NR_listen 50
#define __NR_getsockname 51
用户态和内核态通过系统调用号(49)来确定本次系统调用是哪个功能。
从上面例子来看,glibc将系统调用封装成一个函数(bind),用户态进程的开发者只要调用这个函数即可,并不需要关心具体系统调用是怎么从用户态陷入到内核的,这也体现了linux封装的完善。当然,现代操作系统都会这么封装就是了,要不开发者要疯了。
而封装过程,除了最终陷入到内核时候寄存器的设置(AX必须设置为49)、汇编指令(SYSCALL)不能修改(这是由CPU决定的),其他的都可以由具体sdk决定。上面我们举了glibc的例子,我们再来看一个GOSDK的例子(x86-64):
TEXT ·Syscall(SB),NOSPLIT,$0-56
CALL runtime·entersyscall(SB)
MOVQ a1+8(FP), DI
MOVQ a2+16(FP), SI
MOVQ a3+24(FP), DX
MOVQ $0, R10
MOVQ $0, R8
MOVQ $0, R9
MOVQ trap+0(FP), AX // syscall entry
SYSCALL
CMPQ AX, $0xfffffffffffff001
JLS ok
MOVQ $-1, r1+32(FP)
MOVQ $0, r2+40(FP)
NEGQ AX
MOVQ AX, err+48(FP)
CALL runtime·exitsyscall(SB)
RET
ok:
MOVQ AX, r1+32(FP)
MOVQ DX, r2+40(FP)
MOVQ $0, err+48(FP)
CALL runtime·exitsyscall(SB)
RET
直接就是一个汇编文件。而其系统调用号,也是自己定义了一份,并没有用linux的头文件。
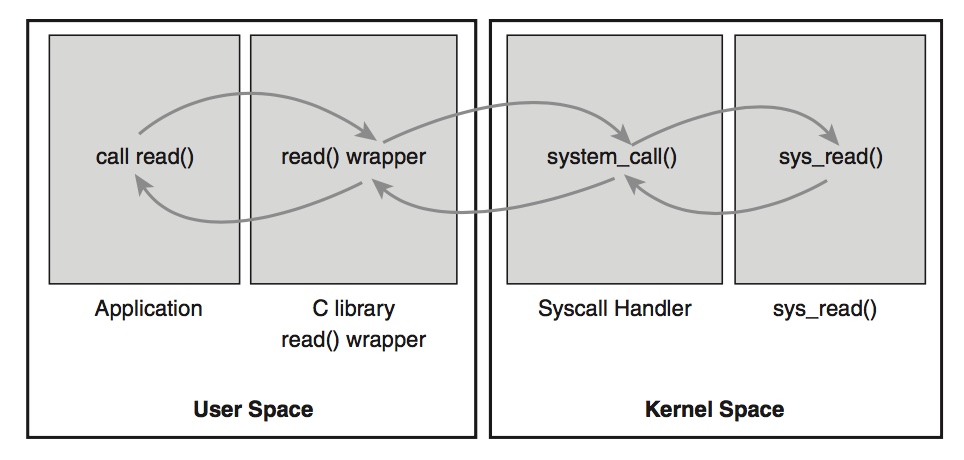
总的来说,用户态的流程是:用户程序 -> glibc/sdk -> 汇编syscall -> 内核,到这里用户态是怎么到内核的流程就梳理完了。下面再来看看内核是怎么处理的。
内核如何分发系统调用
x86-64架构的内核syscall的入口在linux/arch/x86/kernel/entry_64.S。
/*
* 64bit SYSCALL instruction entry. Up to 6 arguments in registers.
*
* 64bit SYSCALL saves rip to rcx, clears rflags.RF, then saves rflags to r11,
* then loads new ss, cs, and rip from previously programmed MSRs.
* rflags gets masked by a value from another MSR (so CLD and CLAC
* are not needed). SYSCALL does not save anything on the stack
* and does not change rsp.
*
* Registers on entry:
* rax system call number
* rcx return address
* r11 saved rflags (note: r11 is callee-clobbered register in C ABI)
* rdi arg0
* rsi arg1
* rdx arg2
* r10 arg3 (needs to be moved to rcx to conform to C ABI)
* r8 arg4
* r9 arg5
* (note: r12-r15,rbp,rbx are callee-preserved in C ABI)
*
* Only called from user space.
*
* When user can change pt_regs->foo always force IRET. That is because
* it deals with uncanonical addresses better. SYSRET has trouble
* with them due to bugs in both AMD and Intel CPUs.
*/
ENTRY(system_call)
..
movq %r10,%rcx
call *sys_call_table(,%rax,8)
movq %rax,RAX(%rsp)
rax中存的就是这次syscall的num,即__NR_bind。system_call简单来说就是跳转到sys_call_table数组中下标为syscall num对应的函数。
sys_call_table在linux/arch/x86/kernel/syscall_64.c定义。
extern void sys_ni_syscall(void);
asmlinkage const sys_call_ptr_t sys_call_table[__NR_syscall_max+1] = {
/*
* Smells like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_syscall_max] = &sys_ni_syscall,
#include <asm/syscalls_64.h>
};
那么,什么时候,将,syscall number对应上sys_xxx的呢?这要看<asm/syscalls_64.h>,这个文件是在v4.11版本是在编译的时候,从linux/arch/x86/entry/syscalls/syscall_64.tbl中生成的。
syscall_64.tbl这个表里是这样定义的:
#
# 64-bit system call numbers and entry vectors
#
# The format is:
# <number> <abi> <name> <entry point>
#
# The abi is "common", "64" or "x32" for this file.
#
0 common read sys_read
1 common write sys_write
2 common open sys_open
3 common close sys_close
...
49 common bind sys_bind
50 common listen sys_listen
51 common getsockname sys_getsockname
52 common getpeername sys_getpeername
编译出来的syscalls_64.h结果为:
__SYSCALL_COMMON(49, sys_bind, sys_bind)
__SYSCALL_COMMON(50, sys_listen, sys_listen)
__SYSCALL_COMMON(51, sys_getsockname, sys_getsockname)
__SYSCALL_COMMON(52, sys_getpeername, sys_getpeername)
__SYSCALL_COMMON(53, sys_socketpair, sys_socketpair)
__SYSCALL_COMMON其实就是__SYSCALL_64,回到前面sys_call_table定义的地方:
#define __SYSCALL_64(nr, sym, qual) extern asmlinkage long sym(unsigned long, unsigned long, unsigned long, unsigned long, unsigned long, unsigned long) ;
#include <asm/syscalls_64.h>
#undef __SYSCALL_64
#define __SYSCALL_64(nr, sym, qual) [ nr ] = sym,
const sys_call_ptr_t sys_call_table[] ____cacheline_aligned = {
/*
* Smells like a compiler bug -- it doesn't work
* when the & below is removed.
*/
[0 ... __NR_syscall_max] = &sys_ni_syscall,
#include <asm/syscalls_64.h>
};
第一个__SYSCALL_64的定义是为了将syscalls_64.h展开为函数声明,之后将__SYSCALL_64重新定义后,是为了将syscalls_64.h展开为数组成员的定义。
所以最终内核得到的,是一个const不可变的sys_call_table数组,下标为syscall number,指向的是内核的sys_call_ptr_t。syscall num从0开始,所以直接根据49就可以找到sys_bind。sys_call_table不可变的目的是为了防止有人篡改系统调用。
这里再谈谈sys_ni_syscall。它在linux/kernel/sys_ni.c定义。sys_bind等符号也是在这个文件里定义的。sys_ni_syscall有其特殊的使命。我们知道用户态和内核态通过系统调用号来约定具体是什么系统调用,那如果随着内核的发展,某些系统调用不再使用怎么办呢?内核规定,系统调用号不能回收,如果不再使用了,系统调用号保留,而对应的系统调用函数则变为sys_ni_syscall,这一功能通过cond_syscall的弱符号来实现。
asmlinkage long sys_ni_syscall(void)
{
return -ENOSYS;
}
..
cond_syscall(sys_socketpair);
cond_syscall(sys_bind);
cond_syscall(sys_listen);
cond_syscall(sys_accept);
cond_syscall(sys_accept4);
cond_syscall(sys_connect);
cond_syscall在linux/include/linux/linkage.h中定义。
#ifndef cond_syscall
#define cond_syscall(x) asm( \
".weak " VMLINUX_SYMBOL_STR(x) "\n\t" \
".set " VMLINUX_SYMBOL_STR(x) "," \
VMLINUX_SYMBOL_STR(sys_ni_syscall))
#endif
cond_syscall中的.weak func() .set func_backup() 的意思是,如果func()不存在,则调用func_backup。具体到bind,即表示如果sys_bind不存在,则调用sys_ni_syscall。
具体系统调用函数的实现
现在内核已经找到了系统调用号49对应的是sys_bind,那么这个函数在哪里定义的呢?
sys_bind的代码在net/socket.c中,不过要看懂还是得费点功夫。
SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen)
{
struct socket *sock;
struct sockaddr_storage address;
int err, fput_needed;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
err = move_addr_to_kernel(umyaddr, addrlen, &address);
if (err >= 0) {
err = security_socket_bind(sock,
(struct sockaddr *)&address,
addrlen);
if (!err)
err = sock->ops->bind(sock,
(struct sockaddr *)
&address, addrlen);
}
fput_light(sock->file, fput_needed);
}
return err;
}
bind函数(!注意,这个函数名字并不是bind,下面会说明,这里只是行文方便)调用move_addr_to_kernel将address从用户态拷贝到内核态,然后调用proto_ops的bind函数来处理bind请求。
函数名不是bind,是什么呢?实际上,SYSCALL_DEFINE3会展开得到sys_bind(int fd, struct sockaddr __user * umyaddr, int addrlen)函数,这样,sys_call_table中才可以用sys_bind。来看linux/include/linux/syscalls.h。
/*
* __MAP - apply a macro to syscall arguments
* __MAP(n, m, t1, a1, t2, a2, ..., tn, an) will expand to
* m(t1, a1), m(t2, a2), ..., m(tn, an)
*/
#define __MAP0(m,...)
#define __MAP1(m,t,a) m(t,a)
#define __MAP2(m,t,a,...) m(t,a), __MAP1(m,__VA_ARGS__)
#define __MAP3(m,t,a,...) m(t,a), __MAP2(m,__VA_ARGS__)
..
#define __MAP(n,...) __MAP##n(__VA_ARGS__)
#define __SC_DECL(t, a) t a
#define __TYPE_IS_L(t) (__same_type((t)0, 0L))
#define __TYPE_IS_UL(t) (__same_type((t)0, 0UL))
#define __TYPE_IS_LL(t) (__same_type((t)0, 0LL) || __same_type((t)0, 0ULL))
#define __SC_LONG(t, a) __typeof(__builtin_choose_expr(__TYPE_IS_LL(t), 0LL, 0L)) a
#define __SC_CAST(t, a) (t) a
#define __SC_ARGS(t, a) a
#define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)
#define SYSCALL_DEFINEx(x, sname, ...) \
SYSCALL_METADATA(sname, x, __VA_ARGS__) \
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)
#define __SYSCALL_DEFINEx(x, name, ...) \
asmlinkage long sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)) \
__attribute__((alias(__stringify(SyS##name)))); \
static inline long SYSC##name(__MAP(x,__SC_DECL,__VA_ARGS__)); \
asmlinkage long SyS##name(__MAP(x,__SC_LONG,__VA_ARGS__)); \
asmlinkage long SyS##name(__MAP(x,__SC_LONG,__VA_ARGS__)) \
{ \
long ret = SYSC##name(__MAP(x,__SC_CAST,__VA_ARGS__)); \
__MAP(x,__SC_TEST,__VA_ARGS__); \
__PROTECT(x, ret,__MAP(x,__SC_ARGS,__VA_ARGS__)); \
return ret; \
} \
static inline long SYSC##name(__MAP(x,__SC_DECL,__VA_ARGS__))
宏定义还挺复杂的。简单来说就是,sys_bind是SyS_bind的别名,在SyS_bind里调用SYSC_bind。所以,将上述代码展开以后,在内核里真正定义的函数是SYSC_Bind。
asmlinkage long sys_bind(int fd, struct sockaddr __user * umyaddr, int addrlen) alias(__stringify(SyS_bind));
static inline long SYSC_bind(int fd, struct sockaddr __user * umyaddr, int addrlen);
asmlinkage long SyS_bind(long fd, long umyaddr, long addrlen);
asmlinkage long SyS_bind(long fd, long umyaddr, long addrlen)
{
long ret = SYSC_bind((int) fd, (struct sockaddr __user *) umyaddr, (int) addrlen);
return ret;
}
static inline long SYSC_bind(int fd, struct sockaddr __user * umyaddr, int addrlen)
据说之所以这么复杂做是为了避免64位CPU寄存器在存储32位值时,可能会因为符号位扩展导致访问非法内存,有安全问题,所以统一用long型字段来接收参数。
再往下就是linux协议栈里bind的实现了,就不在这篇文章中介绍了。
总结
本文讨论了系统调用从用户态通过库函数进入内核的过程,内核如何实现系统调用,以及如何将系统调用传递给真正做事的函数。明白了这一过程,也就明白了如果要新增一个系统调用,需要在哪些地方动手了。
参考:
Linux Kernel Developent second edition, Robert Love
Subscribe via RSS