Linux网络栈解剖(Anatomy of the Linux networking stack)
by 伊布
最近和屈总伯温一起看linux协议栈,正好回忆了下14-15赛季做FTCP的时候看的一些linux network kernel的代码,找到了这篇文章,写的很好。原文为Anatomy of the Linux networking stack, From sockets to device drivers,最早应该是在IBM的Developerworks上的,但现在原始链接已经失效了。
本文是在Google翻译的基础上做的修正。Google翻译实际已经比一般水平的翻译者要靠谱的多,只是某些特定用法需要调整下(例如call, function)。另外我会在文中补充一部分代码,帮助理解。
Linux®操作系统的最大功能之一是其网络栈。它最初是BSD协议栈的衍生物,并且组织良好,具有一组干净的接口。其接口范围从协议无关接口(如通用socket层接口或设备层)到各个网络协议的特定接口。本文从网络栈各层的角度探讨了Linux网络栈的结构,并探讨了其一些主要结构体。
协议介绍
虽然网络的正式介绍通常是指七层开放系统互连(OSI)模型,但是Linux中基本网络栈的介绍使用互联网模型的四层模型(参见图1)。
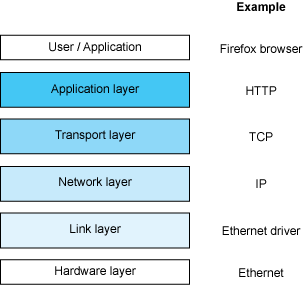
网络栈的底部是链路层。链路层是指提供访问物理层的设备驱动程序(物理层可以是各种各样的介质,诸如串行链路或以太网设备)。链路层上面是网络层,负责将数据包引导到目的地。再上一层是传输层,它负责点对点通信(例如,在主机内,像ssh 127.0.0.1)。网络层管理主机之间的通信,传输层管理这些主机之上的端点(Endpoint)之间的通信。最后是应用层,即可以理解所传输的数据的语义层。
核心网络架构
现在讨论Linux网络栈的架构以及它如何实现Internet模型。图2提供了Linux网络栈的高级视图。顶部是定义网络栈用户的用户空间层或应用层。底部是提供与网络(串行或高速网络(如以太网))连接的物理设备。在中间的内核空间,是本文重点要讨论的网络子系统。通过网络栈的内部流量socket缓冲区(sk_buffs),它们在源和目的之间移动数据包数据。你很快会看到sk_buff结构。
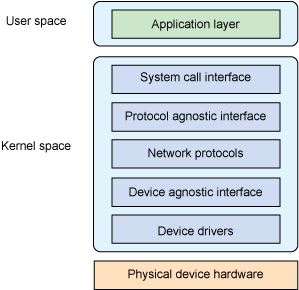
首先简要介绍Linux网络子系统的核心元素,当然后面还会有更详细的介绍。在顶部(见图2)是系统调用接口。这只是为用户空间应用程序提供访问内核网络子系统的一种方式。接下来是一个协议无关的层,提供了一种常用的方法来处理底层的传输层协议。接下来是实际的协议,在Linux中包括TCP,UDP和IP的内置协议。接下来是另一个设备无关的层,它允许使用通用接口与单个设备驱动程序交互,之后是各个设备驱动程序本身。
系统调用接口
系统调用接口可以从两个角度进行描述。当用户进行网络调用时,通过系统调用接口多路复用到内核中。这最终作为 sys_socketcall(./net/socket.c)中的调用,然后进一步解复用到其预期目标的调用。
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen)
SYSCALL_DEFINE2(listen, int, fd, int, backlog)
SYSCALL_DEFINE3(accept, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen)
SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr,
int, addrlen)
...
系统调用接口的另一个角度是使用正常的文件操作进行网络I/O。例如,典型的读写操作可以在网络socket(由文件描述符表示,就像普通文件)一样执行。因此,虽然存在一些特定于网络的操作(调用socket创建socket,调用connect将socket连接到目的地等等),但还是有一些适用于网络对象的标准文件操作,就像常规文件一样。
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.read_iter = sock_read_iter,
.write_iter = sock_write_iter,
struct file *sock_alloc_file(struct socket *sock, int flags, const char *dname)
{
file = alloc_file(&path, FMODE_READ | FMODE_WRITE,
&socket_file_ops);
最后,系统调用接口提供了在用户空间应用程序和内核之间传输控制的手段。
协议无关接口
socket层是协议无关接口,其提供一组通用功能,以支持各种不同的协议。socket层不仅支持典型的TCP和UDP协议,还支持IP,原始以太网和其他传输协议,如流控制传输协议(SCTP)。
网络栈使用socket通信。Linux中的socket结构struct sock是在linux/include/net/sock.h中定义的。该大型结构包含特定socket的所有必需状态,包括socket使用的特定协议以及可能在其上执行的操作。
struct sock {
/*
* Now struct inet_timewait_sock also uses sock_common, so please just
* don't add nothing before this first member (__sk_common) --acme
*/
struct sock_common __sk_common;
#define sk_prot __sk_common.skc_prot
struct proto *sk_prot_creator;
网络子系统通过定义了其功能的特殊结构(即proto)来了解各个可用协议。每个协议维护一个名为proto(在linux/include/net/sock.h中找到)的结构。该结构定义了可以从socket层到传输层执行的特定socket操作(例如,如何创建socket,如何与socket建立连接,如何关闭socket等)。
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
...
网络协议
网络协议部分定义了可用的特定网络协议(如TCP,UDP等)。这些是在linux/net/ipv4/af_inet.c中的inet_init函数的开头进行初始化的(因为TCP和UDP是协议inet族的一部分)。inet_init函数调用proto_register注册每个内置协议。proto_register在linux/net/core/sock.c中定义,除了将协议添加到活动协议列表之外,还可以根据需要分配一个或多个slab缓存。
int proto_register(struct proto *prot, int alloc_slab)
{
if (alloc_slab) {
}
mutex_lock(&proto_list_mutex);
list_add(&prot->node, &proto_list);
assign_proto_idx(prot);
mutex_unlock(&proto_list_mutex);
static int __init inet_init(void)
{
struct inet_protosw *q;
struct list_head *r;
int rc = -EINVAL;
sock_skb_cb_check_size(sizeof(struct inet_skb_parm));
rc = proto_register(&tcp_prot, 1);
if (rc)
goto out;
rc = proto_register(&udp_prot, 1);
if (rc)
goto out_unregister_tcp_proto;
..
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
arp_init();
ip_init();
tcp_init();
udp_init();
...
static struct inet_protosw inetsw_array[] =
{
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT |
INET_PROTOSW_ICSK,
},
您可以通过linux/net/ipv4/中的文件tcp_ipv4.c,udp.c和raw.c中的proto结构来了解各自的协议。这些协议的proto结构体都按照类型和协议映射到inetsw_array,将内部协议映射到对应的操作(which maps the built-in protocols to their operations.)。结构体inetsw_array及其关系如图3所示。该数组中的每个协议都在初始化inetsw时,通过在inet_init调用inet_register_protosw来初始化。函数inet_init还初始化各种inet模块,如ARP,ICMP,IP模块,TCP和UDP模块。
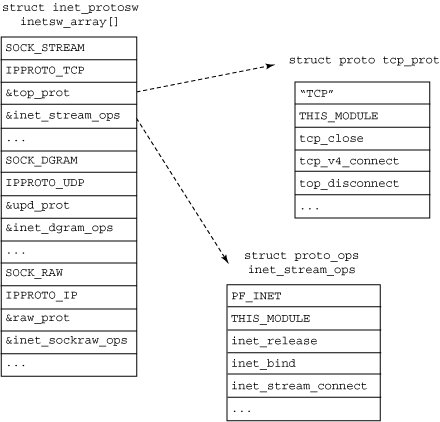
Socket协议关联
回想下,当创建一个socket时,它定义了类型和协议,如 my_sock = socket( AF_INET, SOCK_STREAM, 0 )。其中AF_INET表示基于Internet地址族,SOCK_STREAM表示其为流式socket(如上所示inetsw_array)。
从图3可以看出, proto结构定义了特定传输协议的方法,而proto_ops结构定义了一般的socket方法。其他额外的协议可以通过调用inet_register_protosw将自己加入到inetsw协议开关机(protocol switch) 。例如,SCTP通过在linux/net/sctp/protocol.c中调用sctp_init来添加自己。
补充:prot/prot_ops二者有点相似,这里特意说明下:kernel的调用顺序是先inet(即prot_ops),后protocal(即prot),inet层处于socket和具体protocol之间。下面以connect为例,
ops即为prot_ops,它调用的bind是inet_listen,然后才是具体protocol的tcp_v4_connect。这一关系主要记录在inetsw_array中。
SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr,
int, addrlen)
{
struct socket *sock;
...
err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen,
sock->file->f_flags);
int __inet_stream_connect(struct socket *sock, struct sockaddr *uaddr,
int addr_len, int flags, int is_sendmsg)
{
struct sock *sk = sock->sk;
switch (sock->state) {
case SS_UNCONNECTED:
err = -EISCONN;
if (sk->sk_state != TCP_CLOSE)
goto out;
err = sk->sk_prot->connect(sk, uaddr, addr_len);
if (err < 0)
goto out;
socket的数据移动使用核心结构socket缓冲区(sk_buff)来进行。一个sk_buff 包含包数据(package data),和状态数据(state data, 覆盖协议栈的多个层)。每个发送或接收的数据包都用一个sk_buff来表示。该sk_buff 结构是在linux/include/linux/skbuff.h中定义的,并在图4中示出。
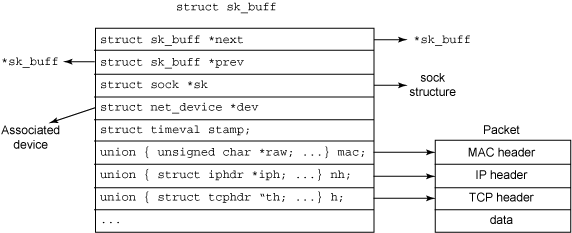
如图所示,一个给定连接的多个sk_buff可以串联在一起。每个sk_buff标识了要发送数据包或从其接收数据包的设备结构(net_device *dev)。由于每个包都表示为一个sk_buff,数据包报头可方便地通过一组指针来寻址(th,iph以及mac(MAC报头)),内核会保证这块内存是连续的。由于sk_buff 是socket数据管理的核心,因此kernel已经创建了许多支撑函数来管理它们,包括sk_buff的创建和销毁,克隆和队列管理等函数。
总的来说,内核socket缓冲器设计思路是,某一的socket的sk_buff串链接在一起,并且sk_buff包括许多信息,包括到协议头的指针,时间戳(发送或接收数据包的时间)以及与数据包相关的网络设备。
设备无关接口
协议层下面是另一个无关的接口层,将协议连接到具有不同功能的各种硬件设备的驱动程序。该层提供了一组通用的功能,由较低级别的网络设备驱动程序使用,以允许它们使用较高级协议栈进行操作。
首先,设备驱动程序可以通过调用register_netdevice/unregister_netdevice将自己注册/去注册到内核。调用者首先填写net_device结构,然后将其传入register_netdevice进行注册。内核调用其init功能(如果有定义),执行许多健全检查,创建一个 sysfs条目,然后将新设备添加到设备列表(在内核中Active设备的链表)。你可以 在linux/include/linux/netdevice.h中找到net_device结构。各个函数在linux/net/core/dev.c中实现。
使用dev_queue_xmit函数将sk_buff从协议层发送到网络设备。dev_queue_xmit函数会将sk_buff添加到底层网络设备驱动程序最终要传输的队列中(网络设备在net_device或者sk_buff->dev中定义)。dev结构包含函数hard_start_xmit,保存用于启动sk_buff传输的驱动程序功能的方法。
通常使用netif_rx接收报文数据。当下级设备驱动程序接收到一个包(包含在新分配的sk_buff)时,内核通过调用netif_rx将sk_buff传递给网络层。然后,netif_rx通过调用netif_rx_schedule将sk_buff排队到上层协议的队列以进行进一步处理。您可以在linux/net/core/dev.c 中找到dev_queue_xmit和netif_rx函数。
最近,在内核中引入了一个新的应用程序接口(NAPI),以允许驱动程序与设备无关层(dev)进行交互。一些驱动程序使用NAPI,但绝大多数仍然使用较旧的帧接收接口(by a rough factor of six to one)。NAPI可以通过避免每个传入帧的中断,在高负载下得到更好的性能。
设备驱动程序
网络栈的底部是管理物理网络设备的设备驱动程序。该层的设备示例包括串行接口上的SLIP驱动程序或以太网设备上的以太网驱动程序。
在初始化时,设备驱动程序分配一个net_device结构,然后用其必需的例程进行初始化。dev->hard_start_xmit就是其中一个例程,它定义了上层如何排队sk_buff用以传输。这个程序需要一个sk_buff。此功能的操作取决于底层硬件,但通常将sk_buff中的数据包移动到硬件环或队列。如设备无关层所述,帧接收使用该netif_rx接口或符合NAPI的网络驱动程序的netif_receive_skb。NAPI驱动程序对底层硬件的功能提出了约束。
在设备驱动程序配置其结构中的dev接口后,调用register_netdevice以后驱动就可以使用了。您可以在linux/drivers/net中找到网络设备专用的驱动程序。
进一步
Linux源代码是了解许多设备类型(包括网络设备驱动程序)的设备驱动程序设计的好方法。您会发现当前内核API的设计和使用方面的变化,但每个API都可用于作为新设备驱动程序的指导或起点。网络栈中的其他代码是常见且可用的,除非您需要新的协议。即使这样,TCP(用于流协议)或UDP(用于基于消息的协议)的实现也是用于开始新开发的有用模型。
(实在不知道作者在这里要表达什么 XD)
网络协议栈的实现,以BSD的实现为佳,代码的结构性更好更严谨,linux大的设计也很好,但是在一些具体问题的实现上稍嫌随意。BSD的实现可以参考 《TCP/IP详解 卷二》,不过除了某些网络设备商会使用BSD的实现(因为开源协议更商业友好),大部分情况下我们要看的还是linux的实现,所以,多看看就熟悉了。
Subscribe via RSS