Spark支持S3作为DataSource(四):使用Spark处理存储在S3上的图片文件
by 伊布
前面三篇文章介绍了S3以及如何使用Hadoop和Spark处理S3上的文本文件,但毕竟我们使用S3的目的是为了处理非结构化文件(图片,视频)。本文介绍了如何使用Spark处理存储在S3某一个bucket里大量文件(实际我只放了很少几张图片)的方法。由于我不了解图片处理算法,所以图片的处理只是简单读取了该图片的长度、宽度、拍摄时间、拍摄地点等信息。至于更复杂的图像处理、视频处理,如车牌识别,如果图像处理算法是纯JAVA的实现,那只是代码复杂度的提升;如果算法是C++的实现,需要将C++嵌入到JVM中,本文不涉及。
实际上编码比较简单,代码量也很小,但由于我不太熟悉Spark App,代码写的不太顺利,另外JavaSparkContext.binaryFiles使用的人很少,故此在这里记录下。
主流程
private static void wordCount(String[] args) {
if (args.length < 1) {
System.err.println("Usage: JavaWordCount <file>");
System.exit(1);
}
SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
ctx.hadoopConfiguration().set("fs.s3a.access.key", "yourAccess");
ctx.hadoopConfiguration().set("fs.s3a.secret.key", "yourKey");
ctx.hadoopConfiguration().set("fs.s3a.connection.ssl.enabled", "false");
ctx.hadoopConfiguration().set("fs.s3a.endpoint", "1.2.3.4:80");
JavaPairRDD<String, PortableDataStream> myRdd = ctx.binaryFiles(args[0]);
List <Tuple2<String, String>> output = myRdd.map(new PicProcess()).collect();
for (Tuple2<?,?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
ctx.stop();
}
- 使用binaryFiles(显然)。这个方法要求参数是一个路径,而非文件,类似于wholeTextFiles而非textFile。其返回值为JavaPairRDD,RDD的(K,V)
- spark-submit时,最后填写的参数是s3路径,如: s3a://zzz/
- JavaPairRDD.map要求一个function,看名字是一个函数/方法,但实际要求的是实现org.apache.spark.api.java.function.Function接口的对象。在这里我给的是一个PicProcess类,代码贴在下面。
- map后得到的是JavaRDD,我的处理比较简单,collect得到list后打印出来。
PicProcess类
PicProcess实现了org.apache.spark.api.java.function.Function接口,主要是其中的call方法。
public class PicProcess
implements org.apache.spark.api.java.function.Function<Tuple2<String, PortableDataStream>, Tuple2<String, String>> {
public Tuple2<String, String> call(Tuple2<String, PortableDataStream> spTuple2) throws Exception {
DataInputStream disFile = spTuple2._2().open();
ImgInfoBean imgInfoBean = null;
try {
Metadata metadata = ImageMetadataReader.readMetadata(disFile);
imgInfoBean = printImageTags(metadata);
} catch (ImageProcessingException e) {
System.err.println("ERR IMAGE PROCESS: " + e);
} catch (IOException e) {
System.err.println("ERR IO: " + e);
}
return new Tuple2<String, String>(spTuple2._1(), imgInfoBean.toString());
}
}
解释下。
org.apache.spark.api.java.function.Function接口只接收2个参数,一个入一个出,但JavaPairRDD入参是2个,所以需要合并组成一个scala.Tuple2;输出时我也希望是K,V的形式(文件名,文件信息),所以也合并组织成一个scala.Tuple2。
call的结构参考下代码,比较简单。
入参的KV中,V的类型是PortaleDataStream,它的open方法返回DataInputStream,可以直接丢给ImageMetadataReader.readMetadata读取图片的meta信息。
图片处理
private ImgInfoBean printImageTags(Metadata metadata)
{
ImgInfoBean imgInfoBean = new ImgInfoBean ();
for (Directory directory : metadata.getDirectories()) {
for (Tag tag : directory.getTags()) {
String tagName = tag.getTagName();
String desc = tag.getDescription();
if (tagName.equals("Image Height")) {
//图片高度
imgInfoBean.setImgHeight(desc);
} else if (tagName.equals("Image Width")) {
...
}
for (String error : directory.getErrors()){
System.err.println("ERROR: " + error);
}
}
return imgInfoBean;
}
private String pointToLatlong (String point ) {
Double du = Double.parseDouble(point.substring(0, point.indexOf("°")).trim());
Double fen = Double.parseDouble(point.substring(point.indexOf("°")+1, point.indexOf("'")).trim());
Double miao = Double.parseDouble(point.substring(point.indexOf("'")+1, point.indexOf("\"")).trim());
Double duStr = du + fen / 60 + miao / 60 / 60 ;
return duStr.toString();
}
这段代码是从open-open那抄的,基本没改。ImgInfoBean就不贴了,直接看链接就好了。
执行结果
提交到YARN上去:
./bin/spark-submit --principal ieevee/zelda1@ZELDA.COM --keytab /etc/security/ieevee.zelda1.keytab --driver-java-options '-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=13838' --jars /home/ieevee/hadoop/hadoop-2.7.2/share/hadoop/tools/lib/aws-java-sdk-1.7.4.jar,/home/ieevee/hadoop/hadoop-2.7.2/share/hadoop/tools/lib/hadoop-aws-2.7.2.jar --class com.ieevee.dthink.ads.zkcfg.HiveJdbcClient --master yarn /home/ieevee/zkcfg-1.0-SNAPSHOT.jar s3a://zzz/
如上,最后一个参数就是我们要处理的S3 bucket。
结果摘录。看上去,虽然s3的bucket里只有2个图片,spark还是分了2个container来执行。Spark的这段调度后面可以看看,如是否很多每个文件一个task。
16/08/05 19:55:17 INFO YarnClientSchedulerBackend: Registered executor NettyRpcEndpointRef(null) (zelda1:44604) with ID 1
16/08/05 19:55:17 INFO BlockManagerMasterEndpoint: Registering block manager zelda1:44854 with 21.3 GB RAM, BlockManagerId(1, zelda1, 44854)
16/08/05 19:55:17 INFO YarnClientSchedulerBackend: Registered executor NettyRpcEndpointRef(null) (zelda2:33312) with ID 2
16/08/05 19:55:17 INFO BlockManagerMasterEndpoint: Registering block manager zelda2:44510 with 21.3 GB RAM, BlockManagerId(2, zelda2, 44510)
...
16/08/05 19:55:21 INFO DAGScheduler: Job 0 finished: collect at HiveJdbcClient.java:258, took 2.675374 s
s3a://zzz/aaa.jpg: [Picture Information]: high:4208 pixels width:3120 pixels recording time:2015:03:07 23:07:15 altitude:0 metres latitude:30.14270833333333 longitude:120.18971944444445
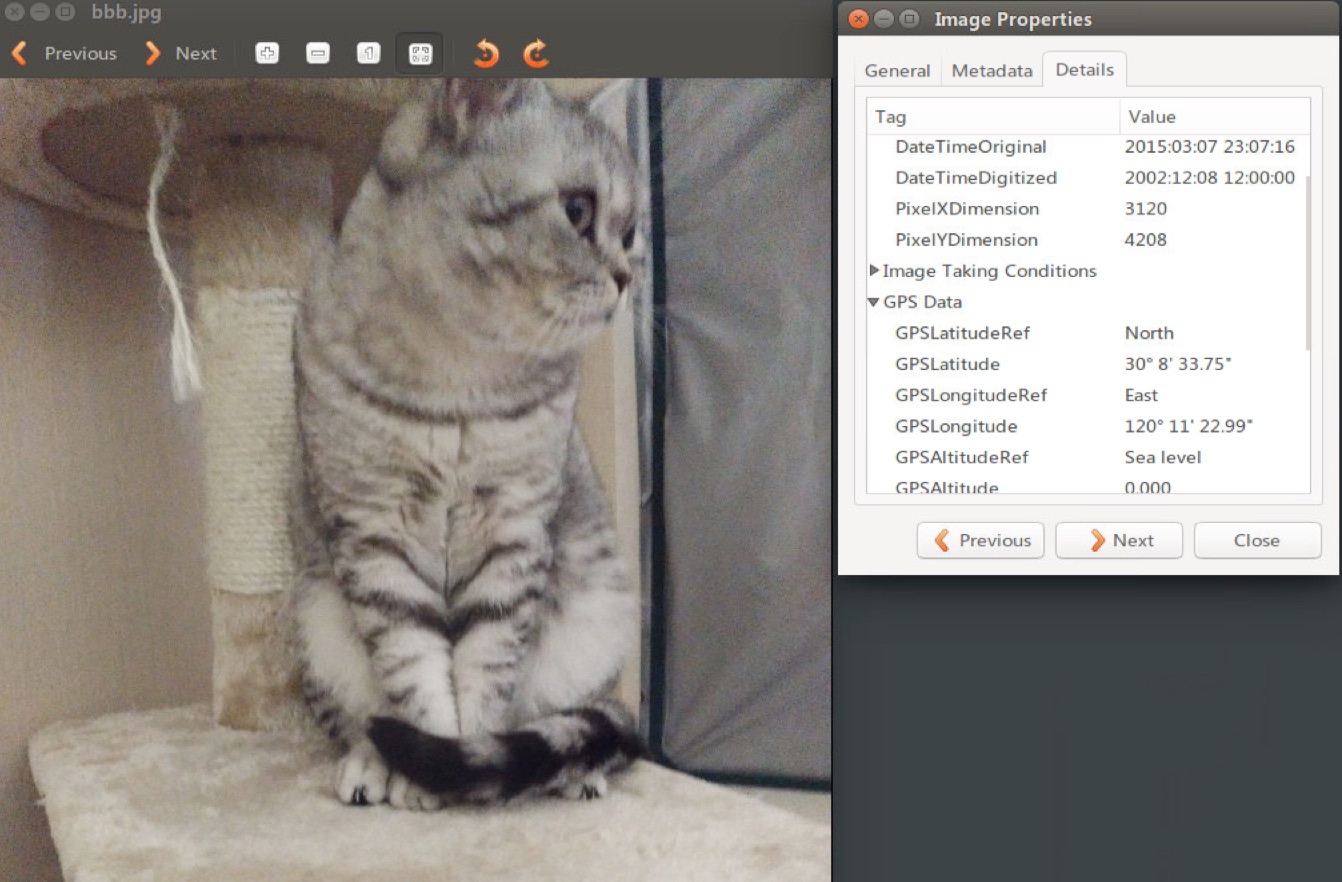
s3a://zzz/bbb.jpg: [Picture Information]: high:4208 pixels width:3120 pixels recording time:2015:03:07 23:07:16 altitude:0 metres latitude:30.14270833333333 longitude:120.18971944444445
来轻松下,比对下其中一张图片的GPS信息:
传送门:
Spark支持S3作为DataSource(一):S3及其开源实现
Spark支持S3作为DataSource(二):Hadoop集成S3 Service
Spark支持S3作为DataSource(三):Spark集成S3 Service
Spark支持S3作为DataSource(四):使用Spark处理存储在S3上的图片文件
Subscribe via RSS