Spark SQL源码走读(一):HiveThriftServer2
by 伊布
start-thriftserver.sh启动thrift server,入口是org.apache.spark.sql.hive.thriftserver.HiveThriftServer2。Spark sql的一些背景说明可以参见这里。
HiveThriftServer2
def main(args: Array[String]) {
logInfo("Starting SparkContext")
SparkSQLEnv.init()
init中创建了SparkContext和HiveContext,并且在sc中增加了listener,用来记录每个stage结束、的信息,代码如下。
var hiveContext: HiveContext = _
var sparkContext: SparkContext = _
def init() {
if (hiveContext == null) {
..
sparkContext = new SparkContext(sparkConf)
sparkContext.addSparkListener(new StatsReportListener())
hiveContext = new HiveContext(sparkContext)
继续,创建hivethriftserver2。主要是cliService,1.6版本可以是http或bin模式,用来给beeline提供服务。ThriftHttpCLIService/ThriftBinaryCLIService只是个通道(要么TCP形式,要么http形式的),服务实际是SparkSQLCLIService提供的。server.init里会将2个service都加到服务链表里,server.start时启动。
这里又给sc加了个listener(可以向注册多个listener,会广播):HiveThriftServer2Listener,它也是继承自SparkListener,跟StatsReportListener记录通用信息不同,它会记录每个sql statement的时间、状态等信息。 thrift server启动后会向spark ui注册一个TAB:“JDBC/ODBC Server”。
try {
val server = new HiveThriftServer2(SparkSQLEnv.hiveContext)
server.init(SparkSQLEnv.hiveContext.hiveconf)
server.start()
logInfo("HiveThriftServer2 started")
listener = new HiveThriftServer2Listener(server, SparkSQLEnv.hiveContext.conf)
SparkSQLEnv.sparkContext.addSparkListener(listener)
uiTab = if (SparkSQLEnv.sparkContext.getConf.getBoolean("spark.ui.enabled", true)) {
Some(new ThriftServerTab(SparkSQLEnv.sparkContext))
对于客户端来说,其实真正提供服务的是SparkSQLCLIService,下面来看看一个beeline是怎么连上来做事的。
SparkSQLSessionManager
SparkSQLCLIService中初始化了backgroundOperationPool(后台op池,后面会用到),并addServer了SparkSQLSessionManager,后者管理sts的会话,例如会在用户登录的时候,新建会话,用户退出关闭会话。SessionManager初始化时,会注册SparkSQLOperationManager,它用来管理:1、会话和hiveContext的关系,根据会话可以找到其hc;2、代替hive的OperationManager管理句柄和operation的关系。 注意Operation只有我们执行SQL的时候才会new一个。
thriftserver可以配置为单会话,即所有beeline共享一个hiveContext,也可以配置为新起一个会话,每个会话独享HiveContext,这样可以获得独立的UDF/UDAF,临时表,会话状态等。默认是新起会话。
新建会话的时候,会将会话和hiveContext的对应关系添加到OperationManager的sessionToContexts这个Map。
只看thrift server的代码还不够,因为它只是“替父出征”,真正在幕后做调度的其实还是被extend的hive的代码,二者要结合来看。以一次SQL执行来看:
CLIService根据句柄找到Session并执行statement
public class CLIService extends CompositeService implements ICLIService {
@Override
public OperationHandle executeStatement(SessionHandle sessionHandle, String statement,
Map<String, String> confOverlay)
throws HiveSQLException {
OperationHandle opHandle = sessionManager.getSession(sessionHandle)
.executeStatement(statement, confOverlay);
LOG.debug(sessionHandle + ": executeStatement()");
return opHandle;
}
每次statement执行,都是新申请的operation,都会加到OperationManager去管理。newExecuteStatementOperation被SparkSQLOperationManager.newExecuteStatementOperation覆盖了,创建的operation实际是SparkExecuteStatementOperation。
public class HiveSessionImpl implements HiveSession {
@Override
public OperationHandle executeStatement(String statement, Map<String, String> confOverlay)
throws HiveSQLException {
return executeStatementInternal(statement, confOverlay, false);
}
private OperationHandle executeStatementInternal(String statement, Map<String, String> confOverlay,
boolean runAsync)
throws HiveSQLException {
acquire(true);
OperationManager operationManager = getOperationManager();
ExecuteStatementOperation operation = operationManager
.newExecuteStatementOperation(getSession(), statement, confOverlay, runAsync);
OperationHandle opHandle = operation.getHandle();
try {
operation.run();
opHandleSet.add(opHandle);
return opHandle;
} catch (HiveSQLException e) {
..
}
operation.run的执行过程:
public abstract class Operation {
public void run() throws HiveSQLException {
beforeRun();
try {
runInternal();
} finally {
afterRun();
}
}
前面把cliservice、session、operation、statement理清楚了,下面来看看具体的statement执行者SparkExecuteStatementOperation。
如前所述,一个Operation分三步:beforeRun、runInternal、afterRun,两头现在只是用来记录日志,直接看runInternal。默认为异步,即后台执行,SparkExecuteStatementOperation创建一个Runable对象,并将其提交到里面backgroundOperationPool,新起一个线程来做excute。
excute中最主要的是hiveContext.sql(statement),其他一些管理事务,如通知listener记录statement的信息,设置operation的状态。
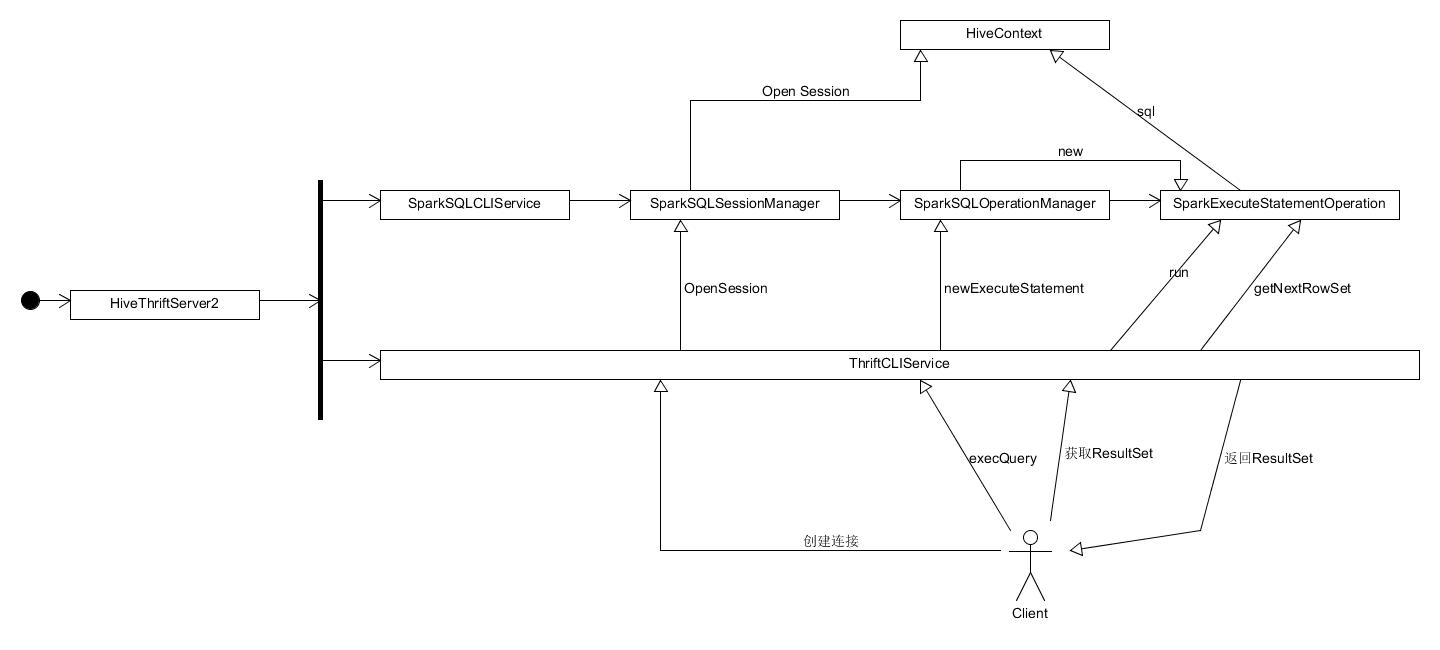
综上,spark thriftserver在hiveContext上套了一层友好的SQL命令行的壳,用户只要通过beeline或JDBC执行SQL即可,不需要看到spark SQL内部的细节(例如hiveContext、sqlContext)。盗用下别人的图,关系整理的很好:
spark-hive-thriftserver里还有个SparkSQLCLIDriver,是在spark-sql里用的,现在还用不到。
Subscribe via RSS