Spark(十):Hive on Spark配置
by 伊布
Spark与Hive有两种搭配方式,一是我们目前采用的spark thrift server读取hive metastore(Spark SQL),由spark项目组主导;二是hive on spark,即hive将其执行引擎从tez改为spark,由hive项目组主导。当然更早还有shark,不过已经没人用了。Databricks有篇文章谈到了二者的未来,可以参考。
从一些测试结果来看,spark sql和hive on spark的性能差距不大,而后者由于入口是hive,相对来说更成熟(使用者多,完善的权限管理等),对于现存的大量hadoop原有用户来说,吸引力更大,如果是已有hadoop的环境上,可以使用spark替换执行引擎,获取更好的性能。
但不可忽视的是,毕竟hive on spark是受制于Hive的框架的,而Spark可能也支持力度不够,长远来看,Spark SQL应该还是更有潜力。Databricks原文:
In short, we firmly believe Spark SQL will be the future of not only SQL, but also structured data processing on Spark. We are hard at work and will bring you a lot more in the next several releases. And for organizations with legacy Hive deployments, Hive on Spark will provide them a clear path to Spark.
下面记录了Hive on spark的配置过程,坑略多。
版本对应关系
我的:
hadoop:2.7.2 spark:1.6.1 hive:2.0.0
一定要注意版本配套!!! 比较简单的办法是download源码查一下pom文件对应组件的version,检查是否支持。
配置方式
1、重新编译spark,去掉对hive的支持、去掉thrift-server。
./make-distribution.sh --tgz "-Pyarn,hadoop-2.6"
官方给的命令里加了-Phadoop-provided,这个参数会让编译出来的assembly包不包含hadoop的一些组件,例如zk和hadoop自己,不要用,否则spark启动的时候会提示找不到hadoop的一些类。编译出来的assembly包,不能再启动sts。
2、配置yarn
要求为公平调度。修改{hadoop_home}/etc/hadoop/yarn-site.xml。
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
3、配置hive
3.1 配置执行引擎 默认hive的执行引擎是tez,需要修改为spark。我的办法是在启动hiveserver2的时候指定(一些材料里提到也可以在hive-site.xml里增加这个配置项,你可以试试):
./bin/hiveserver2 --hiveconf hive.execution.engine=spark
3.2 配置SPARK_HOME
export SPARK_HOME=/home/ieevee/spark/spark-1.6.1-bin-hadoop2.6
默认hiveserver会使用yarn,可以不配置spark.master参数。注意hive on spark是yarn-cluster模式, 即spark driver(sparkContext)和YARN的ApplicationMaster在一起。
过程分析及集群角色划分
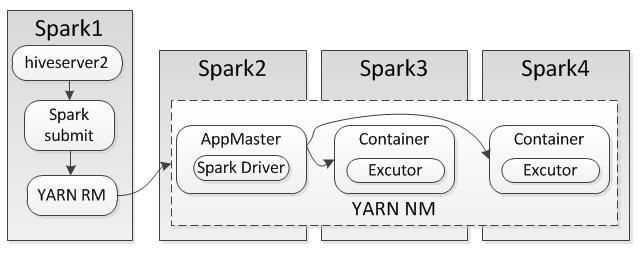
- hiveserver2启动,指定engine=spark
- beenline登录到hiveserver2上,可以查看DB、表、scan表。此时无任何Spark计算。
- 查询select count(*) from xxx,hiveserver2向yarn提交任务,在spark1(master)上可以看到SparkSubmit任务
- YARN选择在一个node manager上启动Container,运行YARN ApplicationMaster;也是这个Container,运行Spark Driver(SparkContext),二者在同一个进程中。
- AppMaster向YARN提交新Excutor请求,在这个Excutor中执行Spark Task(参考下图)。

Cloudera的这篇文章可能会有比较大的帮助。这篇文章也很好的阐述了yarn-cluster和yarn-client的区别。
日志路径
调试过程中遇到问题,循着控制流查找日志吧少年。
hiveserver2: /tmp/{username}/hive.log
AppMaster(即spark-client、Spark driver): {hadoop_home}/logs/userlogs/application_../container_../stderr
Container(即spark excutor): {hadoop_home}/logs/userlogs/application_../container_../stderr 由于YARN是公平调度,如果有多个nodemanager,那么AppMaster和各个Container会尽量均匀分布到不同的节点上。
官方说明。
遇到的一些错误
1、spark的excutor启动时,提示找不到HADOOP_HOME,但实际已经设置了。 这个问题没解决,目前不影响使用。
16/05/19 09:52:36 INFO executor.CoarseGrainedExecutorBackend: Registered signal handlers for [TERM, HUP, INT]
16/05/19 09:52:36 DEBUG util.Shell: Failed to detect a valid hadoop home directory
java.io.IOException: HADOOP_HOME or hadoop.home.dir are not set.
at org.apache.hadoop.util.Shell.checkHadoopHome(Shell.java:302)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:327)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:79)
at org.apache.hadoop.yarn.conf.YarnConfiguration.<clinit>(YarnConfiguration.java:590)
at org.apache.spark.deploy.yarn.YarnSparkHadoopUtil.newConfiguration(YarnSparkHadoopUtil.scala:66)
at org.apache.spark.deploy.SparkHadoopUtil.<init>(SparkHadoopUtil.scala:52)
at org.apache.spark.deploy.yarn.YarnSparkHadoopUtil.<init>(YarnSparkHadoopUtil.scala:51)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at java.lang.Class.newInstance(Class.java:383)
at org.apache.spark.deploy.SparkHadoopUtil$.liftedTree1$1(SparkHadoopUtil.scala:396)
at org.apache.spark.deploy.SparkHadoopUtil$.yarn$lzycompute(SparkHadoopUtil.scala:394)
at org.apache.spark.deploy.SparkHadoopUtil$.yarn(SparkHadoopUtil.scala:394)
at org.apache.spark.deploy.SparkHadoopUtil$.get(SparkHadoopUtil.scala:411)
at org.apache.spark.executor.CoarseGrainedExecutorBackend$.run(CoarseGrainedExecutorBackend.scala:151)
at org.apache.spark.executor.CoarseGrainedExecutorBackend$.main(CoarseGrainedExecutorBackend.scala:253)
at org.apache.spark.executor.CoarseGrainedExecutorBackend.main(CoarseGrainedExecutorBackend.scala)
16/05/19 09:52:36 DEBUG util.Shell: setsid exited with exit code 0
2、spark的driver打印AbstractMethodError。 查了下日志,excutor启动时会向driver的storageMaster注册,driver收到后直接异常了。原因是这里用的hive 1.2.1对应spark1.3,而实际在跑的系统是spark1.6.1;excutor按1.6.1发送事件给1.3的driver,就挂啦。 解决办法是使用hive2.0版本,虽然其对应spark1.5,但是在我的spark1.6上跑的也挺欢的。
16/05/19 09:52:40 ERROR Utils: uncaught error in thread SparkListenerBus, stopping SparkContext
java.lang.AbstractMethodError
at org.apache.spark.scheduler.SparkListenerBus$class.onPostEvent(SparkListenerBus.scala:62)
at org.apache.spark.scheduler.LiveListenerBus.onPostEvent(LiveListenerBus.scala:31)
at org.apache.spark.scheduler.LiveListenerBus.onPostEvent(LiveListenerBus.scala:31)
at org.apache.spark.util.ListenerBus$class.postToAll(ListenerBus.scala:55)
at org.apache.spark.util.AsynchronousListenerBus.postToAll(AsynchronousListenerBus.scala:37)
at org.apache.spark.util.AsynchronousListenerBus$$anon$1$$anonfun$run$1$$anonfun$apply$mcV$sp$1.apply$mcV$sp(AsynchronousListenerBus.scala:80)
at org.apache.spark.util.AsynchronousListenerBus$$anon$1$$anonfun$run$1$$anonfun$apply$mcV$sp$1.apply(AsynchronousListenerBus.scala:65)
at org.apache.spark.util.AsynchronousListenerBus$$anon$1$$anonfun$run$1$$anonfun$apply$mcV$sp$1.apply(AsynchronousListenerBus.scala:65)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:57)
at org.apache.spark.util.AsynchronousListenerBus$$anon$1$$anonfun$run$1.apply$mcV$sp(AsynchronousListenerBus.scala:64)
at org.apache.spark.util.Utils$.tryOrStopSparkContext(Utils.scala:1180)
at org.apache.spark.util.AsynchronousListenerBus$$anon$1.run(AsynchronousListenerBus.scala:63)
16/05/19 09:52:51 ERROR LiveListenerBus: SparkListenerBus has already stopped! Dropping event SparkListenerExecutorMetricsUpdate(1,WrappedArray())
Subscribe via RSS