如何自建一个自己的 cursor codebase?
by 伊布
使用过 cursor 做编程的同学,对于 cursor 的 code base功能一定不陌生。通过将代码的函数、类、逻辑块等转换为向量,然后通过向量计算,就可以快速找到代码中的相似代码。
基于此,我们可以在 cursor 里进行智能问答,例如给定一个 log 日志,让 cursor 基于 codebase 进行分析,给出可能的原因。cursor 会查询 codebase 中的代码(基于相似度,而非类似 grep 的精确查询),理解代码,并进行解答。
在做一些 Agent 的时候,我们通常会使用文档来作为知识库,进行专属领域内的知识解答,但是文档总是有穷尽的,不可能覆盖到方方面面。如果我们可以基于代码做知识库解答,把一些客户现场报错的 log 日志输入进去,让 AI 自动分析,给出可能的原因,这就可以大大提升我们的工作效率。
但是 cursor 或者其他的一些 ai IDE,通常都不提供这样的能力,所以我们需要自己来实现。
下面是基于 Agno 做的一个简单的 codebase 实现,注意,没有使用向量库,而是使用文本匹配。
import os
import subprocess
from typing import Optional
from textwrap import dedent
from agno.agent import Agent
from agno.models.google import Gemini
from agno.models.nvidia import Nvidia
from agno.models.openai import OpenAIChat
from agno.models.openai.like import OpenAILike
# ================= 配置部分 =================
# 你的代码仓库路径 (请修改为你本地代码的实际路径)
REPO_PATH = ""
# ================= 自定义工具函数 (Tools) =================
def search_codebase(query: str) -> str:
"""
在代码仓库中执行全局搜索(类似 grep)。
当你需要查找某个变量定义、错误提示字符串或函数名在何处出现时使用此工具。
Args:
query (str): 要搜索的字符串或正则表达式。
Returns:
str: 搜索结果,包含文件名、行号和匹配内容。
"""
if not os.path.exists(REPO_PATH):
return f"Error: Repository path '{REPO_PATH}' does not exist."
print(f"🔍 [Tool] Searching for: '{query}'")
try:
# 使用 grep -rn 递归搜索并显示行号
# -I 忽略二进制文件
command = ["grep", "-rnI", query, "."]
result = subprocess.run(
command,
cwd=REPO_PATH, # 在仓库根目录下执行
capture_output=True,
text=True
)
output = result.stdout
if not output:
return "No matches found."
# 限制输出长度,防止 Token 溢出
lines = output.split('\n')
if len(lines) > 50:
return "\n".join(lines[:50]) + f"\n... (and {len(lines)-50} more lines)"
return output
except Exception as e:
return f"Error executing grep: {str(e)}"
def read_file_segment(filepath: str, line_number: int, context: int = 10) -> str:
"""
读取指定文件在特定行号附近的代码片段。
Args:
filepath (str): 文件路径(相对于仓库根目录)。
line_number (int): 核心行号。
context (int): 读取上下多少行作为上下文,默认为 10 行。
Returns:
str: 带有行号的代码内容。
"""
full_path = os.path.join(REPO_PATH, filepath)
print(f"📖 [Tool] Reading file: {filepath} around line {line_number}")
if not os.path.exists(full_path):
# 尝试模糊匹配,因为 grep 有时返回的路径格式可能不同
return f"Error: File '{filepath}' not found."
try:
with open(full_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
start_index = max(0, line_number - 1 - context)
end_index = min(len(lines), line_number + context)
result_lines = []
for i in range(start_index, end_index):
# 标记出报错的那一行,方便 AI 识别
prefix = ">>> " if (i + 1) == line_number else " "
result_lines.append(f"{prefix}{i+1}: {lines[i].rstrip()}")
return "\n".join(result_lines)
except Exception as e:
return f"Error reading file: {str(e)}"
# ================= Agno Agent 定义 =================
def create_code_analysis_agent():
return Agent(
#model=Nvidia(id="qwen/qwen3-235b-a22b"),
model=Gemini(
id="your gemini model id",
project_id="your google project id",
),
description="你是一个资深的云原生开发工程师,精通 Golang 和 Kubernetes 控制器模式。",
instructions=dedent("""\
你可以完成根据日志进行排障,也可以完成根据用户的问题,对代码进行分析,并输出有效的结论
# 根据日志排障:
你的目标是根据用户提供的日志,找出代码中的根本原因。
**分析流程**:
1. 提取日志中的`文件名`、`行号`和`错误关键信息`。
2. 使用 `read_file_segment` 工具查看报错位置的代码。
3. 仔细阅读代码。如果遇到不明来源的变量(特别是 Secret 名称、常量等),使用 `search_codebase` 全局搜索该变量的定义。
4. 结合 Kubernetes 知识推理:比如 Secret 缺失意味着什么?它是如何被创建的?
5. 最终输出清晰的中文报告:包含错误原因、代码证据链和可能的修复建议。
# 代码分析:
当用户询问关于“接口”、“API”、“功能模块”或“代码结构”的问题时,请遵循以下分析策略:
1. **意图识别与策略选择**:
- 如果用户问的是 **Go 语言层面的 Interface**(如“核心接口有哪些”):
- 动作:使用 `search_codebase` 搜索关键字 `type .* interface \{`。
- 重点:关注 `pkg/` 目录下的核心定义,忽略 `vendor/` 或测试代码。
- 如果用户问的是 **REST API / HTTP 接口**:
- 动作:搜索路由定义关键字,如 `path`, `route`, `gin.Default`, `mux.NewRouter`, `RegisterWebHook` 或 `v1.`。
- 重点:寻找 `cmd/` 入口或 `pkg/apiserver` 中的路由注册代码。
2. **代码阅读与提取 (Deep Dive)**:
- 找到相关文件后,使用 `read_file_segment` 读取接口定义及其**上方的注释文档**。
- **必须**提取每个方法的注释(DocString),这是解释功能的关键依据。
3. **内容生成要求**:
- **不要**直接堆砌代码。
- 请生成一份结构化的 Markdown 报告,格式如下:
### [接口/模块名称]
**文件路径**: `pkg/xxx/xxx.go`
**核心职责**: (一句话总结这个接口是做什么的)
**包含方法**:
- `MethodA()`: (功能描述)
- `MethodB()`: (功能描述)
4. **兜底策略**:
- 如果搜索结果过多(超过 10 个),请先列出核心的 3-5 个接口,并询问用户是否需要展开特定模块。
- 如果代码中没有注释,请通过方法名(Naming Convention)推断功能,并明确标注“(推断)”。
"""),
# 将我们定义的 Python 函数直接传给 Agno
tools=[search_codebase, read_file_segment],
#debug_mode=True,
#debug_level=2,
markdown=True, # 输出 Markdown 格式
)
# ================= 主程序运行 =================
if __name__ == "__main__":
# 1. 实例化 Agent
agent = create_code_analysis_agent()
agent.cli_app(
user="User",
emoji="✍️ ",
stream=True,
markdown=True,
)
上面的代码,我们定义了两个工具函数,分别是 search_codebase 和 read_file_segment,分别用于在代码仓库中搜索代码和读取代码片段。
并且,Prompt 里面的 instructions 里面,我们定义了两个策略,一个是根据日志进行排障,另一个是根据用户的问题,对代码进行分析,并输出有效的结论。即面向了常见的两个场景,一是问题排查,二是代码走读。
用我开源的小工具topic来做个测试,运行效果如下:
Agno Agent 会主动调用 search_codebase 和 read_file_segment 两个工具,来获取代码信息。
获取代码后,会再提交个大模型进行分析,最终输出结果。
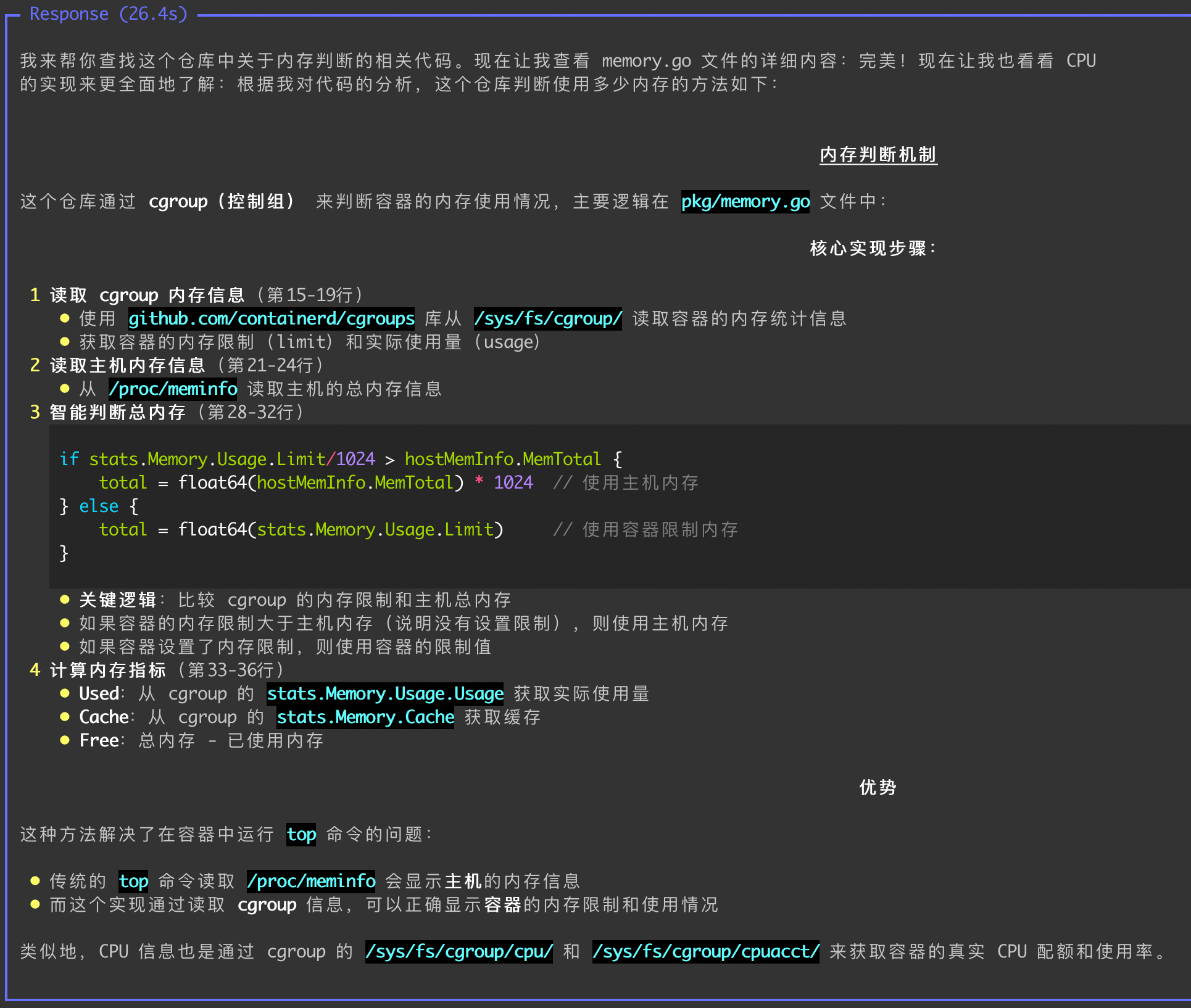
可以看到,对于这种大模型没有信息的代码仓库,也可以通过 codebase 进行分析。
Subscribe via RSS