http cache在Dragonfly中的应用
by 伊布
阿里开源的Dragonfly对k8s集群上多副本应用的镜像分发有很大帮助,通过p2p网络,可以很好的解决docker registry的压力。
有关蜻蜓的介绍,请参见直击阿里双11神秘技术:PB级大规模文件分发系统“蜻蜓”
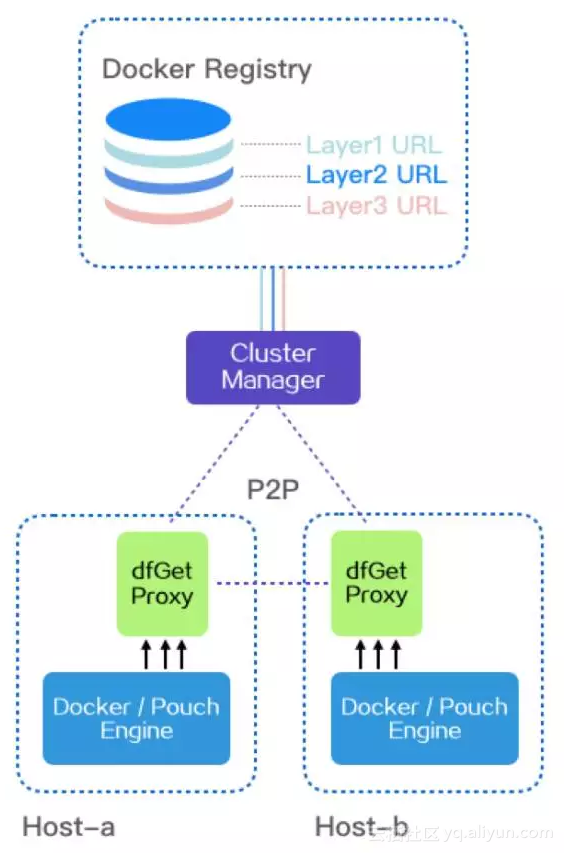
首先,docker pull命令,会被dfget proxy截获。然后,由dfget proxy向super node(即cluster manager)发送调度请求,super node在收到请求后会检查对应的下载文件是否已经被缓存到本地,如果没有被缓存,则会从Registry中下载对应的文件,并生成种子分块数据(种子分块数据一旦生成就可以立即被使用);如果已经被缓存,则直接生成分块任务,请求者解析相应的分块任务,并从其他peer或者supernode中下载分块数据,当某个Layer的所有分块下载完成后,一个Layer也就下载完毕了,同样,当所有的Layer下载完成后,整个镜像也就下载完成了。
看了两天蜻蜓的代码,尝试分析一下其缓存的机制。
supernode的缓存有2级。
第一级是 repo/download,对应cdn过程。第一次下载镜像时,由于super node没有任何数据,所以会触发cdn过程,即若干个client发起的请求到达super node后,会由super node统一下载,下载的文件会存储在这个目录下。由于是super node统一下载,所以会很节省机房间的带宽(只pull了一份),但同时super node也可能会成为瓶颈。
第二级是repo/upload,对应p2p过程。super node下载文件后,会将该文件upload到repo/upload目录下,之后与各个节点组成p2p网络,加速各个节点的pull过程。因此,当应用有较多副本时,通过p2p加速会带来非常好的效果,从蜻蜓的数据来看,基本上可以认为pull时间没有明显的变化。
有缓存就必然有老化。
先说第二级,相对比较简单。super node会启动data gc,它每隔3分钟检查一下repo/upload下的文件对应的task是否还存在(即是否还有人在pull)。
这里有一个问题:如何判断不同节点上pull同一层(同一个blob)时,是不是同一个task呢?实际上,蜻蜓在生成task id时,主要是根据url(以及其他一些辅助项),因此不同节点pull同一层时,其task id是一致的。
因此,当所有节点都pull结束后,过3-6分钟,repo/upload下的文件就会被gc掉,老化结束。之后如果再有节点pull该镜像,则需要重新开启p2p流程,重新往repo/upload下上传文件(当然了,实际是做了一个link)。
那么第一级,即cdn是怎么老化的呢?蜻蜓在这里使用了http cache的机制,与一般浏览器判断网页是否老化的机制是一致的。
http cache是什么机制呢?下面摘录浏览器缓存详解:expires,cache-control,last-modified,etag详细说明里的说明:
浏览器下载网页或者文件如css,第一次下载时,服务器会返回http 200和文件,同时如果服务器支持缓存的话会在响应消息里带 last modify或者etag头。
Last-Modified
在浏览器第一次请求某一个URL时,服务器端的返回状态会是200,内容是你请求的资源,同时有一个Last-Modified的属性标记(HttpReponse Header)此文件在服务期端最后被修改的时间,格式类似这样:
Last-Modified:Tue, 24 Feb 2009 08:01:04 GMT
客户端第二次请求此URL时,根据HTTP协议的规定,浏览器会向服务器传送If-Modified-Since报头(HttpRequest Header),询问该时间之后文件是否有被修改过:
If-Modified-Since:Tue, 24 Feb 2009 08:01:04 GMT
如果服务器端的资源没有变化,则自动返回HTTP304(NotChanged.)状态码,内容为空,这样就节省了传输数据量。当服务器端代码发生改变或者重启服务器时,则重新发出资源,返回和第一次请求时类似。从而保证不向客户端重复发出资源,也保证当服务器有变化时,客户端能够得到最新的资源。
Etag
HTTP协议规格说明定义ETag为“被请求变量的实体标记”
简单点即服务器响应时给请求URL标记,并在HTTP响应头中将其传送到客户端,类似服务器端返回的格式:
Etag:“5d8c72a5edda8d6a:3239″
客户端的查询更新格式是这样的:
If-None-Match:“5d8c72a5edda8d6a:3239″
如果ETag没改变,则返回状态304。
last modify比较好理解,本质上就是个时戳。那么etag呢?我将其理解为文件的digest。例如从harbor registry中下载blob时,应答消息会带etag字段,其内容实际就是blob文件的sha 256 digest。下次再请求该blob时,如果带上 If-None-Match: {etag},registry判断etag相同,文件没有变化,直接返回304即可。
可以把蜻蜓看做浏览器,在cdn过程中,当第二次请求该文件时,蜻蜓会先向registry发起请求,携带 last modify或者etag头,如果浏览器返回的是304,则认为http cache没有老化(或者cache hit),不需要重新下载;否则认为已经老化,重新发起downloader进行分片下载。
当然,如果你在用蜻蜓的时候发现总是cache miss,那是因为蜻蜓在这里有个bug,只处理了last modify,没有处理etag。我提交了PR,已经merge进去了。
Subscribe via RSS