OpenVswitch设计与实现
by 伊布
- Abstract
- 1 Introduction
- 2 设计约束和基本原理
- 3 设计
- 4 流缓存设计(Flow Cache Design)
- 5 缓存敏感的包分类器(Caching-aware Packet Classification)
- 6 缓存失效(Cache Invalidation)
- 7 Evaluation
- 8 Ongoing, Future, and Related Work
- 9 Conclusion
注:原文为 The Design and Implementation of Open vSwitch ,是Open Vswitch团队2015年在NSDI大会上发表的论文,详细的讲述了Open Vswitch为了解决性能问题所做的若干实践。论文对理解ovs的源码帮助很大,为了方便我自己阅读,做了简单的翻译工作。翻译的比较乱,如果有觉得不爽的地方,可以给我提issue或者直接PR。
Abstract
我们描述了Open vSwitch的设计和实现,这是一个适用于所有主要虚拟机管理程序平台的多层开放源虚拟交换机。 Open vSwitch在虚拟环境中被重新设计用于网络连接,导致主要设计偏离了传统的软件交换架构。 我们详细介绍了Open vSwitch用来优化其操作并节省虚拟机管理程序资源的高级流分类和缓存技术。 我们评估Open vSwitch的性能,从我们过去七年使用和改进Open vSwitch的部署经验中得出。
1 Introduction
过去15年来,虚拟化改变了我们的计算方式; 例如,许多数据中心都完全虚拟化,以提供快速配置,向云端扩展,并在灾难恢复期间提高可用性。尽管虚拟化仍然可以覆盖所有类型的工作负载,但虚拟机的数量已经超过了服务器的数量,进一步的虚拟化显示没有停止的迹象[1]。
服务器虚拟化的兴起带来了数据中心网络的根本转变。 一个新的网络接入层已经出现,其中大多数网络端口是虚拟的,而不是物理的[5] - 因此,用于工作负载的第一跳交换机越来越多地驻留在hypervisor中。 在早期,这些hypervisor的“vSwitches”主要关心提供基本的网络连接。 实际上,他们只是通过将物理L2网络扩展到常驻虚拟机来模拟他们的ToR表亲。随着虚拟化workloads的激增,这种方法的局限性变得明显:为新workloads重新配置和准备物理网络会减慢配置速度,并且将工作负载与物理L2段耦合严重限制了它们的移动性和可伸缩性,使其与底层网络的移动性和可伸缩性限制在一起。
这些压力导致了网络虚拟化的出现[19]。 在网络虚拟化中,虚拟交换机成为虚拟机网络服务的主要提供者,使物理数据中心网络在hypervisors之间传输IP隧道数据包。 这种方法允许虚拟网络与其基础物理网络分离,并且通过利用通用处理器的灵活性,虚拟交换机可以为虚拟机,其租户和管理员提供与专用物理网络相同的逻辑网络抽象、服务和工具网络。
网络虚拟化需要有能力的虚拟交换机 - 转发功能必须根据每个虚拟端口进行连线,以便与管理员配置的逻辑网络抽象相匹配。 在虚拟机管理程序中实现这些抽象,也从细化的集中协调中受益匪浅。 这种方法与早期的静态的、硬编码转发管道的虚拟交换机形成鲜明对比,已经完全足以为虚拟机提供到物理网络的L2连接。
正是在这种背景下:虚拟网络日益复杂,网络虚拟化的出现以及现有虚拟交换机的局限性,使Open vSwitch能够迅速普及。 今天,在Linux平台上,Open vSwitch与大多数hypervisors 和容器系统(包括Xen,KVM和Docker)协同工作。 Open vSwitch也可以在FreeBSD和NetBSD操作系统上“开箱即用”,并且VMware ESXi和Microsoft Hyper-V hypervisors的移植正在进行中。
在本文中,我们描述Open vSwitch的设计和实现[26,29]。 其设计的关键要素围绕Open vSwitch的常规生产环境所需的性能以及网络虚拟化所要求的可编程性。传统的网络应用通过专业的软件或硬件来实现高性能,相比之下,Open vSwitch都是为灵活性和通用用途而设计的。 它必须在没有专业化的情况下实现高性能,适应所支持平台的差异,同时与hypervisors及其workloads共享资源。 因此,本文首先关注这种悬念 - Open vSwitch如何在不牺牲一般性的情况下获得高性能。
在本文的其余部分安排如下。 第2部分提供了关于虚拟化环境的更多背景,而第3部分描述了Open vSwitch的基本设计。 之后,第4,5和6节描述了Open vSwitch设计如何通过流缓存优化虚拟化环境的要求,缓存如何对包括报文分类器在内的整个设计产生广泛影响,以及Open vSwitch如何管理其流缓存。 然后,第7部分通过分类和缓存的 micro-benchmarks,评估了Open vSwitch的性能,以及提供了多租户数据中心中Open vSwitch性能的view(?)。 在结束之前,我们将在第8节中讨论正在进行的,将来的和相关的工作。
2 设计约束和基本原理
虚拟交换机的运行环境与传统网络设备的环境截然不同。 下面我们简要讨论这些差异带来的限制和挑战,以揭示Open vSwitch设计选择背后的基本原理,并突出展示它的独特之处。
资源共享。 传统网络设备的性能目标有利于使用专用硬件资源在最坏情况下实现线路性能(line rate)的设计。 虚拟交换机与之不同,资源节约至关重要。 交换机是否能跟上最坏情况的线路速率(line rate)是次要的,更重要的是最大化利用Hypervisors的资源:运行用户工作负载。 也就是说,与物理环境相比,虚拟化环境中的网络更聚焦于优化常见情况,而不是优化最坏情况。 这并不是说最坏的情况并不重要,因为它们确实会在实践中出现。 端口扫描,P2P集合服务器和网络监控都会生成异常的流量模式,但必须得到优雅的支持。 这个原则导致我们例如大量使用流缓存和其他形式的缓存,这在一般情况下(具有高命中率)减少CPU使用率并提高转发速率。
放置。虚拟交换机在网络边缘的放置既是简化又是复杂性的根源。 可以说,拓扑位置作为一片与虚拟机管理程序和虚拟机共存亡的叶子,可惜消除许多标准的网络问题。 但是,放置会使缩放(scaling)复杂化。单个虚拟交换机在 hypervisorss 之间的点对点IP隧道网络中,拥有数千个虚拟交换机作为其对等体的情况,并不罕见。 当虚拟机启动,迁移和关闭时,虚拟交换机接收转发状态更新,而虚拟交换机相对较少(通过网络标准)物理网络端口直接连接,远程虚拟机监控程序中的更改可能会影响本地状态。特别是在数千个(或更多) hypervisorss 的大型部署中,转发状态可能会持续不断更新。本文讨论的受此原则影响的设计的主要例子是Open vSwitch分类算法,该算法专为O(1)更新而设计。
SDN,用例和生态系统。 Open vSwitch有三个额外的独特要求,最终导致其设计与其他虚拟交换机不同:
首先,Open vSwitch自成立以来一直是OpenFlow交换机。 它被故意不绑定到一个单一用途,紧密集成的网络控制堆栈,而是通过Open-Flow [27]重新编程。 这与其他虚拟交换机的功能数据通路模型相反[24,39]:类似于转发ASIC,它们的报文处理流水线是固定的。 只有预先配置的功能才有可能。 (可以通过添加二进制模块来扩展Hyper-V虚拟交换机[24],但通常每个模块仅向datapath(datapath)添加另一个单一用途功能。)
在SDN的早期,OpenFlow的灵活性至关重要,但很快发现,高级用例(如网络虚拟化)会导致较长的数据包处理流水线,从而导致比传统虚拟交换机更高的分类负载。 为了防止Open vSwitch比竞争对手的虚拟交换机消耗更多的管理程序资源,它被迫实现流缓存。
第三,与任何其他主要虚拟交换机不同,Open vSwitch是开放源代码和多平台。 与所有在单一环境中运行的闭源虚拟交换机相反,Open vSwitch的环境通常由选择操作系统分发和管理程序的用户选择。 这迫使Open vSwitch设计非常模块化和便携。
3 设计
3.1 概览
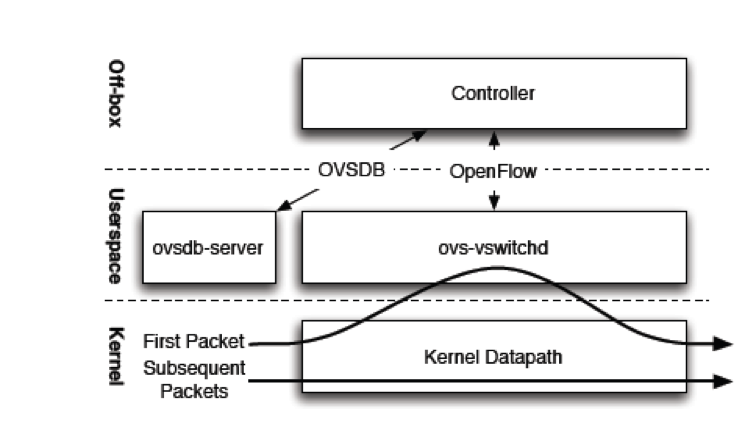
图1:Open vSwitch的组件和接口。 流的第一个数据包导致未命中,内核模块将数据包定向到用户空间组件,该组件将后续数据包的转发决策缓存到内核中。
在Open vSwitch中,主要有两个组件指导数据包转发。 第一个也是更大的组件是ovs-vswitchd,它是一个用户空间守护进程,不同操作系统基本相同。 另一个主要组件 - datapath内核模块通常为不同操作系统专门编码,以提高性能。
图1描述了两个主要的OVS组件如何一起工作来转发数据包。 内核中的datapath模块首先从物理网卡或虚拟机的虚拟网卡接收数据包。 ovs-vswitchd指示datapath如何处理这种类型的数据包,或者它没有。 在前一种情况下,datapath模块简单地遵循由ovs-vswitchd给出的称为actions的指令,该actions列出了要在其上发送报文的物理端口或隧道。 actions还可以指定数据包修改,数据包采样或丢弃数据包的指令。 在后一种情况下,如果datapath未被告知如何处理数据包,则将其传送到ovs-vswitchd。 在用户态,ovs-vswitchd确定数据包应该如何处理,然后将数据包和包所需的处理方法传回给datapath。 通常,ovs-vswitchd还会通知datapath缓存actions,以处理类似的未来数据包。
在Open vSwitch中,流缓存(flow caching)随着时间的推移发生了很大变化; 最初的datapath是一个微流缓存(a microflow cache),实质上是为每个传输连接的转发决定都建立缓存。 在后来的版本中,datapath具有两层缓存:微流缓存和称为megaflow缓存的辅助层,缓存超出单个连接的流量聚合的转发决策。 我们将在第4节更详细地了解缓存。
Open vSwitch通常用作SDN交换机,控制转发的主要方式是OpenFlow [27]。通过一个简单的二进制协议,OpenFlow允许控制器添加,删除,更新,监控和获取流量表及其流量的统计信息,并将选定的数据包上送到控制器,并将控制器中的数据包注入到交换机。
在Open vSwitch中,ovs-vswitchd从SDN控制器接收OpenFlow流表,将从datapath模块接收的所有数据包与这些OpenFlow表匹配,收集所应用的actions,最后将结果缓存到内核datapath中。这允许datapath模块不知道OpenFlow有线协议(wire protocal)的细节,进一步简化它。
从OpenFlow控制器的角度来看,缓存和用户态/内核态分离,是不可见的实现细节:在控制器视图中,每个数据包访问一系列OpenFlow流表,并且交换机查找满足数据包的条件最高的优先流,并执行其OpenFlow actions。
Open vSwitch的流程编程模型在很大程度上决定了它可以支持的用例,为此,Open vSwitch对标准OpenFlow进行了许多扩展以适应网络虚拟化。 我们将很快将讨论这些扩展,但在此之前,我们将重点放在此设计的性能关键方面:数据包分类(Packet Classification)和内核用户空间接口。
3.2 包分类
在通用处理器上计算(Algorithmic?)包分类是昂贵的,并且由于匹配形式的普遍性,OpenFlow环境中的包分类尤其昂贵,这可能会测试以下属性的任何组合:以太网地址,IPv4和IPv6的地址,TCP和UDP端口以及许多其他字段,包括数据包元数据,例如交换机入口端口。
Open vSwitch对其所有数据包分类都使用元组空间搜索(tuple space search, TSS)分类器[34],内核和用户空间都是。 为了理解元组空间搜索(TSS)的工作原理,假设Open vSwitch流中的所有流都以相同的方式匹配相同的字段,例如,所有流都匹配源和目标以太网地址,但没有其他字段。元组搜索分类器将这样的流表实现为单个哈希表。 如果控制器添加具有不同匹配形式的新流,则分类器将创建第二个散列表,该散列表在这些流中匹配的字段上散列化。 (元组空间搜索分类器中的哈希表的元组恰好是形成该哈希表的密钥的字段集合,但我们通常将哈希表本身称为元组,作为一种有用的简写形式)。 如果有两个哈希表,那么必须在两个哈希表中搜索查找。如果都没有匹配,则都不包含可以匹配的流(flow); 如果只在一个哈希表中存在匹配项,则该流是符合结果的匹配项; 如果两个哈希表都有匹配项,则结果是具有较高优先级的流。随着控制器继续使用新的匹配形式添加更多流,分类器同样为每个唯一匹配规则(unique match)增加哈希表,并且分类器的搜索必须在每个哈希表中查找。
虽然元组空间搜索的查找复杂度远不如现有技术水平[8,18,38],但我们在实践中看到其流表性能良好,并且在决策树分类算法上具有三个有吸引力的特性。 首先,它的更新是时间固定的(更新转换为单个哈希表操作),这使得它适合与集中式控制器经常添加和移除流的虚拟化环境一起使用,(有时每个hypervisor每秒更新多次) ,以响应整个数据中心的变化。 其次,元组空间搜索可以推广到任意数量的数据包头字段,而不需要任何算法改变。 最后,元组空间搜索使用的内存随着流的数量线性增长。
复杂的SDN控制器使用的大量流表进一步放大了分组分类的相对成本。 例如,在VMware网络虚拟化控制器[19]安装的流量表的数据包处理管道中,每个数据包至少查找15个表。 长管道由两个因素驱动:通过叉积(cross-product)来缩短阶段往往会显着增加流量表大小和开发人员对模块化管道设计的偏好(reducing stages through cross-producting would often significantly increase the flow table sizes and developer preference to modularize the pipeline design. )。 因此,比提高单个分类器查找的性能更重要的是,平均而言,减少单个数据包所需查找的流表数量。
3.3 3.3 使用OpenFlow作为编程模型
最初,Open vSwitch专注于被动(reactive)流程编程模型:响应流量的控制器安装匹配每个支持的OpenFlow字段的 microflows 。
这种方法很容易支持软件交换机和控制器,早期的研究表明它是足够的[3]。 但是, microflows 的被动式编程很快就证明在小型部署之外使用是不切实际的,Open vSwitch必须适应主动流编程来限制其性能成本。
没看懂。
在OpenFlow 1.0中,microflow有大约275 bits,因此每个微流的流表可以有 2的275次方 个或更多的条目。 因此,流量表的 proactive population 需要支持通配符匹配来覆盖所有可能数据包的头部空间。
使用单个表会导致“cross-product问题”:根据字段A的n1值和字段B的n2值来改变数据包的处理方式,在一般情况下,必须安装n1×n2个数据流,即使 基于A和B采取的行动是独立的。 Open vSwitch很快就引入了一个称为resubmit的扩展action,允许数据包查阅多个流表(或多次同一个表),从而汇总最终的操作。 这解决了叉积的问题,因为A表可以包含n1条流,而B表包含n2条流。
resubmit action可以基于一个或多个字段的值,启用基于多路分支的编程形式。 后来,专注于硬件的OpenFlow供应商想方设法更好地利用转发ASIC所提供的多个表格,并且OpenFlow 1.1引入了多表支持。 Open vSwitch采用了新模型,但为了向后兼容的考虑,仍保留了其resubmit action的支持,因为新模型不允许递归,而只是通过固定表管道来转发报文。
此时,控制器可以在Open vSwitch流表中实现编程,该程序可以使用任意逻辑链来根据数据包头作出决定,但他们无法访问临时存储。 为了解决这个问题,Open vSwitch以另一种方式扩展OpenFlow,通过添加流量表可以匹配的称为“寄存器(registers)”的元数据字段,以及修改和复制它们的附加actions。 例如,通过这种方式,流可以在pipeline早期确定一个物理目的地,然后通过相同的包处理步骤来处理报文,直到发送报文为止,而发送报文时可能使用特定于目的地的Action(flows could decide a physical destination early in the pipeline, then run the packet through packet processing steps identical regardless of the chosen destination, until sending the packet, possibly using destination-specific instructions. )。作为另一个例子,VMware的NVP网络虚拟化控制器[19]使用寄存器通过逻辑L2和L3拓扑来跟踪数据包的处理,逻辑L2和L3拓扑实现为逻辑datapath,并将其叠加在物理OpenFlow流水线上。
没看懂。
OpenFlow专门用于对交换机进行基于流量的控制。 它不能创建或销毁OpenFlow交换机,添加或移除端口,配置QoS队列,关联OpenFlow控制器和交换机,启用或禁用STP(生成树协议)等。在Open vSwitch中,此功能通过单独的组件进行控制:配置数据库。 为了访问配置数据库,SDN控制器可以通过OVSDB协议连接到ovsdb-server[28],如图1所示。一般来说,在Open vSwitch中,OpenFlow可以控制潜在的快速变化和短暂的数据,例如 作为流表,而配置数据库则包含更持久的状态。
4 流缓存设计(Flow Cache Design)
本节介绍Open vSwitch中流缓存的设计以及它如何演进到当前状态。
4.1 Microflow Caching
在2007年,当在Linux上开始开发Linux vSwitch的代码时,只有内核数据包转发才能真正实现良好的性能,因此最初的实现将所有OpenFlow处理都放到了内核模块中。 该模块接收来自NIC或VM的数据包,通过Open-Flow表(使用标准OpenFlow匹配和操作)进行分类,根据需要对其进行修改,最后将其发送到另一个端口。 由于在内核中开发以及分发和更新内核模块相对困难,这种方法很快变得不切实际。 很明显,内核的OpenFlow实现作为对上游Linux的贡献是不可接受的,这是采用内核组件的软件的重要要求。
我们的解决方案是将内核模块重新实现为一个微流缓存(microflow cache),其中单个缓存条目表达式与OpenFlow支持的所有数据包表头字段匹配。 这通过将内核模块实现为简单的哈希表而不是复杂的通用数据包分类器来支持任意字段和掩码,从而实现了根本性的简化。 在这种设计中,高速缓存条目非常细致,并且与单个传输连接的大部分数据包相匹配:即使对于单个传输连接,网络路径的更改以及IP TTL字段中的更改都会导致未命中, 数据包发送给用户空间,该用户空间查询实际的OpenFlow流表以决定如何转发它。 这意味着关键性能维度是流设置时间,即内核向用户空间报告微流“未命中”以及用户空间回复的时间。
在多个Open vSwitch版本中,我们采用了多种技术来减少微流缓存的流量建立时间。 例如,通过减少建立给定微流所需的系统调用的平均数量,达到的分批流设置提高了24%的流设置性能。 最后,我们还通过多个用户空间线程分配流量设置负载,以从多个CPU内核中受益。 从CuckooSwitch [42]绘制插图,我们采用乐观并发cuckoo哈希[6]和RCU [23]技术来实现无阻塞多读取器,单写入器流表。
在对这种客户反馈进行普遍优化之后,我们将注意力集中在对延迟敏感的应用程序的性能上,这就要求我们重新考虑简单的缓存设计。
4.2 Megaflow Caching
虽然微流高速缓存在大多数流量模式下运行良好,但在大量短连接的情景下,性能会严重下降。 在这种情况下,很多数据包会错过缓存,并且不仅要跨越内核用户空间边界,还要执行一系列昂贵的数据包分类。 虽然批处理和多线程可以稍微缓解这种压力,但它们不足以完全支持这种工作负载。
我们用megaflow缓存替换了微流缓存。 megaflow缓存是一个支持通用匹配的单流查找表,即它支持对比较大的流量聚合进行缓存转发决策。由于它支持任意数据包字段匹配,它与微流缓存相比,更接近通用的OpenFlow表,但由于两个主要原因,它在运行时仍然非常简单和轻便。首先,它没有优先级,这会加快数据包分类:内核元组空间搜索(TSS)实现可以在发现任何匹配时立即终止,而不是继续查找更高优先级的匹配,直到所有掩码特定的哈希表格被检查。 (为了避免歧义,用户空间只安装不相交的megaflows,这些megaflows的匹配规则不会有重叠)。其次,只有一个megaflow分类器,而不是分类器管道,所以用户空间安将相关的Openflow表重构后,再将megaflow表项安装到内核。(Second, there is only one megaflow classifier, instead of a pipeline of them, so userspace installs megaflow entries that collapse together the behavior of all relevant OpenFlow tables.)。
megaflow查找的成本接近通用数据包分类器,尽管它缺少对流量优先级的支持。搜索megaflow分类器需要搜索每个哈希表直到找到匹配; 正如3.2节所讨论的那样,流表中的每种独特类型的匹配在分类器中产生一个散列表。假设每个散列表包含匹配的可能性相同,匹配的包需要平均搜索(n + 1)/ 2个表,并且不匹配的包需要搜索所有n个表。因此,对于n> 1,通常情况下,基于分类器的megaflow搜索需要比微流缓存查找更多的哈希表。Megaflows本身就产生了一种折衷:必须打赌,per-microflow虽然避免了访问用户空间,但其成本仍然比额外查询更多hash表的megaflow要高。
Open vSwitch通过将微流缓存保留为第一级缓存来解决megaflow的成本问题,并在megaflow缓存之前先查询微流缓存。 微流缓存是一个哈希表,从微流映射到其匹配的megaflow。 所以,在微流中的第一个数据包搜索内核分类器、通过内核megaflow表后,这个完全匹配缓存(即微流缓存)允许相同微流中的后续数据包快速定向到合适的megaflow。 这降低了从每个数据包到每个微流的成本。 完全匹配缓存是一个真正的缓存,因为它的活动对用户空间不可见,除了对性能有影响。
megaflow流表表示所有用户空间OpenFlow流表的叉积(cross-product )的活动子集。 为了避免主动叉积计算的成本,并仅使用与当前转发的流量相关的条目填充megaflow缓存,Open vSwitch用户空间守护程序逐渐计算并反应性(reactively)地计算缓存条目。 由于Open vSwitch通过用户空间流表处理数据包,并在每个表中对数据包进行分类,因此它会跟踪作为分类算法一部分被查询的数据包字段位。 生成的megaflow必须匹配作为决策一部分的任何字段(或字段的一部分)的值。 例如,如果分类器将任何一个OpenFlow表中的IP目标字段视为其pipeline的一部分,则megaflow高速缓存条目的条件也必须与目标IP相匹配。这意味着缓存填充是由传入数据包驱动的,随着流量聚合(as the aggregates of the traffic evolve),将填充新条目并删除旧条目。
前面的讨论掩盖了一些细节。 基本算法虽然正确,但会产生比所需更具体的匹配条件,这会导致缓存命中率不理想。 下面的第5节描述了Open vSwitch如何修改元组空间搜索以产生更好的megaflows进行缓存。 之后,第6节解决缓存失效问题。
5 缓存敏感的包分类器(Caching-aware Packet Classification)
我们现在把重点放在我们对基本元组搜索算法的改进和改进上(总结在第3.2节),以提高其适用于流缓存。
5.1 问题
由于Open vSwitch用户空间通过其OpenFlow表处理数据包,因此它将跟踪作为转发决策时一部分被查阅的数据包字段位。 这种按比特分组报头字段的跟踪在使用简单的OpenFlow流表构建megaflow条目时非常有效。
例如,如果OpenFlow表只查看以太网地址(就像基于L2 MAC学习的流表一样),那么它生成的megaflows也只会查看以太网地址。例如,端口扫描(不会改变以太网地址)不会导致数据包进入用户空间,因为它们的L3和L4标头字段将被通配,导致接近理想的megaflow缓存命中率。然而,如果表中即使有一个流表项匹配TCP目标端口,元组空间搜索也会考虑每个数据包的TCP目标端口。 然后,每个megaflow都将在TCP目标端口上匹配,并且端口扫描性能再次下降。
我们不知道有效的在线算法来生成最优,最不具体的megaflows,因此在开发过程中,我们将注意力集中在生成越来越好的近似值上。 未能匹配必须包含的字段会导致不正确的数据包转发,从而导致的错误是无法接受的,所以我们的近似值偏向于更多的、超过必要的字段的匹配。 以下部分描述了我们已集成到Open vSwitch中的这种类型的改进。
5.2 元组优先级排序(Tuple Priority Sorting)
在元组空间搜索分类器中查找通常需要搜索每个元组。 即使搜索早期元组已经发现有匹配的流,搜索仍然必须查看其他元组,因为其中一个元组可能包含具有更高优先级的匹配流。
注:元组tupple是一组相同匹配规则的流的组合。
我们通过在每个元组T中跟踪在该T中的任何流条目的最大优先级T.pri_max来改进。
我们修改了查找代码,按元组的T.pri_max从大到小来查找各个元组,以查找能够匹配包的流F(该流的优先级为F.pri);如果下一个元组的T.pri_max不大于当前流的F.pri,查找就可以终止了, 因为后面的元组没有更好的匹配了(即使有匹配的流,其优先级也低于当前查找的流)。 图2详细显示了该算法。

图2: Tuple space search for target packet headers H, with priority sorting.
举个例子,我们检测了一个部署在生产环境上的由VMware的NVP控制器安装的OpenFlow表[19]。
该表包含29个元组。
在这29个元组中,26个包含单个优先级的流,这具有直观意义,因为匹配单个元组的流倾向于share a purpose,因此是优先级(which makes intuitive sense because flows matching a single tuple tend to share a purpose and therefore a priority. )。当按优先级降序搜索时,可以在这样的元组成功匹配后立即终止。
其他元组中,有两个元组是包含具有两个唯一优先级的流,这些优先级高于任何后续元组中的任何优先级,因此这些元组中的任何匹配均会终止搜索。
最终一个元组包含从32767到36866的五个独特优先级的流量; 在最坏的情况下,如果在这个元组中匹配到的是最低优先级的流,那么还必须搜索剩余所有的T.pri_max > 32767的元组(该元组在排序列表中后面还有20个元组)。
//注
struct pvector_entry {
int priority;
void *ptr;
};
static const struct cls_rule *
classifier_lookup__(const struct classifier *cls, ovs_version_t version,
struct flow *flow, struct flow_wildcards *wc,
bool allow_conjunctive_matches)
{
...
PVECTOR_FOR_EACH_PRIORITY (subtable, hard_pri + 1, 2, sizeof *subtable,
&cls->subtables) {
#define PVECTOR_FOR_EACH_PRIORITY(PTR, PRIORITY, N, SZ, PVECTOR) \
for (struct pvector_cursor cursor__ = pvector_cursor_init(PVECTOR, N, SZ); \
((PTR) = pvector_cursor_next(&cursor__, PRIORITY, N, SZ)) != NULL; )
static inline void *pvector_cursor_next(struct pvector_cursor *cursor,
int lowest_priority,
size_t n_ahead, size_t obj_size)
{
if (++cursor->entry_idx < cursor->size &&
cursor->vector[cursor->entry_idx].priority >= lowest_priority) {
if (n_ahead) {
pvector_cursor_lookahead(cursor, n_ahead, obj_size);
}
return cursor->vector[cursor->entry_idx].ptr;
}
return NULL;
}
5.3 分阶段查找(Staged Lookup)
元组空间搜索使用散列表查找来搜索每个元组。 在我们构造megaflow匹配条件的算法中,这个哈希表查找意味着即使元组搜索失败,megaflow也必须匹配包含在元组中的字段的所有位,因为这些字段和它们中的每一个位都可能影响查找结果。 当元组匹配一个经常变化的字段(例如,TCP源端口)时,生成的megaflow并不比安装微流更有用,因为它只会匹配单个TCP流。
这指出了一个改进的机会。 如果可以在其字段的一个子集上搜索元组,并通过此搜索确定元组不可能匹配,则生成的megaflow只需要匹配字段的子集,而不是元组中的所有字段。
由于元组实现为一个使用所有字段的hash表,这样的优化是很困难的,因为不能在其关键字的子集上搜索哈希表。 我们考虑了其他数据结构。 一个 trie 将允许搜索字段的任何前缀,但它也会增加成功搜索所需的内存访问次数:从O(1)变为O(n),n为元组字段长度。 每个field建立一个哈希表(Individual per-field hash tables)具有相同的缺点。 我们没有考虑大于O(n)的数据结构(n为元组流中的数量),因为OpenFlow表可能有数十万个流。
我们实现的解决方案是,按照流量粒度的降序将元数据(例如,交换机入口端口),L2,L3和L4静态分为四组。 我们将每个元组从单个哈希表更改为四个哈希表的数组,称为阶段(stages):一个元数据字段,一个元数据和L2字段,一个元数据,L2和L3字段,以及一个全字段。 (后者与前一个实现中的单个哈希表相同。) 元组中的查找按顺序搜索每个阶段。 如果任何搜索出现不匹配的情况,那么对元组的整体搜索也会失败;并且只有包含在最后搜索阶段的字段才能添加到megaflow匹配中(If any search turns up no match, then the overall search of the tuple also fails, and only the fields included in the stage last searched must be added to the megaflow match.)。
这种优化技术可以应用于支持字段的任何子集,而不仅仅是我们使用的基于layer的子集。 我们按照协议层划分字段,是因为根据经验,在TCP/IP中,内层头部往往比外层头部更加多样化。 例如,在L4处,TCP源端口和目标端口基于每个连接而改变,但是在元数据层中仅存在相对较小且静态的入口接口(ingress ports)数量。
元组中的每个阶段都包含早期阶段的所有字段。 我们选择了这种做法,尽管这个技术并不需要它。这样做的原因是,散列可以从一个阶段到下一个阶段递增计算,并且分析表明散列计算是一个重要的成本(有或没有staging)。
因为查找分为了四个阶段,人们可能会说搜索元组的时间会增加四倍。 我们的测量表明,实际上分类速度在实践中还略微提高了,因为当搜索在任何早期stages终止时,分类器不必计算由该元组覆盖的所有字段的完整散列。
这个优化修复了生产部署中出现的性能问题。 NVP控制器使用Open vSwitch实现多个隔离的逻辑datapath(进一步互连以形成逻辑网络)。 每个逻辑datapath都是独立配置的。 假设某些逻辑datapath配置了允许或拒绝基于L4(例如TCP或UDP)端口号的流量的ACL。 这些逻辑datapath上的流量Megaflow必须匹配L4端口才能执行ACL。 其他逻辑datapath上的流量的Megaflow不需要,并且为了性能,不应该在L4端口上匹配。 但是,在此优化之前,所有生成的megaflow都与L4端口匹配,因为分类器搜索必须通过与L4端口匹配的元组。 该优化允许megaflow在没有L4 ACL的逻辑dadapath上进行通信,以避免在L4端口上进行匹配,因为前三个(或更少)阶段足以确定不存在匹配。
注:也就是说,对于那些不匹配L4的flow,确实做到了查找时不需要在L4上查找的效果。另,上文的逻辑datapath,并不是实际的datapath。上述优化发生在一个classifier的一个subtable里。(As another example, VMware’s NVP network virtualization controller [19] uses registers to keep track of a packet’s progress through a logical L2 and L3 topology implemented as “logical datapaths” that it overlays on the physical OpenFlow pipeline.)
5.4 Prefix Tracking
OpenFlow中的流经常匹配IPv4和IPv6子网来实现路由。 当所有匹配该字段时都使用相同的子网大小,例如全部匹配/16子网,这对于构建megaflow来说可以很好地工作。 然而,如果不同的流匹配不同的子网大小,就像任何标准的IP路由表一样,构造的megaflow匹配最长的子网前缀,例如,任何主机路由(/32)强制所有megaflows匹配完整地址。 举个例子,假设Open vSwitch正在为发往10.5.6.7的数据包构建一个megaflow。 如果流需要匹配子网10/8和主机10.1.2.3/32,则可以安全地安装一个用于10.5/16的megaflow(因为10.5/16完全位于10/8内并且不包括10.1.2.3),但如果没有额外的优化,Open vSwitch只能安装10.5.6.7/32。 (为了清楚起见,我们的示例仅使用八位字节前缀,例如/8,/16,/24,/32,但后面显示的实现和伪代码根据位前缀(bit prefix)进行工作。)
我们使用trie结构实现了IPv4和IPv6字段的前缀优化。 如果流表匹配IP地址,则分类器会在元组空间搜索之前先执行任何此类字段的LPM查找,以确定所需的最大megaflow前缀长度,以及确定哪些元组可完全跳过而不影响正确性。(这是为了提高清晰度而进行的轻微简化; 实际实现是,如果包含匹配IP字段的staged lookup已经结束,则将恢复为prefix tracking。) 作为示例,假设OpenFlow表包含与某些IPv4字段匹配的流,如下所示:
20 /8
10.1 /16
10.2 /16
10.1.3 /24
10.1.4.5/32
这些流程对应于以下trie,其中实心圆表示上面列出的地址匹配项之一,虚线圆圈表示仅存在于其子项的节点:
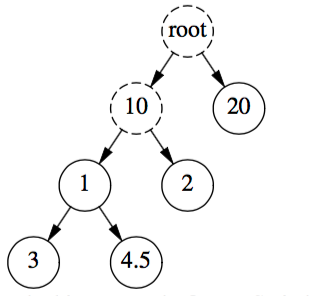
要确定要匹配的位,Open vSwitch将从根节点穿过具有匹配数据包IP地址中相应位的标签的节点。 如果遍历到达一个叶节点,则megaflow不需要匹配余下的地址位,例如,在我们的例子中,10.1.3.5将匹配10.1.3/24,而20.0.5.1将匹配20/8。 另一方面,如果由于地址中的位与树中的任何相应标签都不匹配导致遍历停止,则必须构建megaflow以匹配包括无法找到的位,例如为10.3.5.1构建10.3/16,为30.10.5.2构建30/8。
tire搜索还允许Open vSwitch跳过搜索某些元组。 考虑地址10.1.6.1。对于这个地址的上述trie的搜索终止于标记为1的节点,无法找到匹配地址的第三个八位字节的节点。 这意味着流表中没有任何能匹配IP地址超过16位的流,因此分类器查找可以跳过以上列出的具有/24和/32前缀的流搜索元组。

图3. 前缀跟踪伪代码。 该功能搜索以root节点为根的trie中的value(例如,IP地址)。 它返回必须检查的value开始处的位数,以使其匹配节点具有唯一性,并返回可能匹配长度的位数组。 在伪代码中,x[i]是x中的第i位,len(x)中是x中的bit数。
图3给出了前缀匹配算法的详细伪代码。 假定每个节点都有成员bits,该节点中的bits(至少一个bit,除了根节点可以是空的); left和right,节点的子节点(或NULL); 和n_rules,节点中的规则数量(如果节点只是为了表示子节点,则为零,否则为非零)。 如上所述,它返回必须匹配的位数,从而允许megaflows得到改善,以及一个位数组,其中的0位指定元组的匹配长度,Open vSwitch可能会据此跳过搜索(a bit-array in which 0-bits designate matching lengths for tuples that Open vSwitch may skip searching, as described above)。
虽然此算法是为了优化最长前缀匹配查找,但即使没有流明确匹配IP前缀,它也可以改善megaflow。 为了在OpenFlow中实现最长的前缀匹配,具有较长前缀的流必须具有较高的优先级,这将允许5.2节中的元组优先级排序优化在找到最长匹配之后跳过前缀匹配表,但这仅导致megaflows无法根据表格中最长的前缀进行位通配(but this alone causes megaflows to unwildcard address bits according to the longest prefix in the table)。 然后,该算法的主要优点是阻止应用于特定主机的策略(例如高优先级ACL)强制所有megaflow匹配完整的IP地址。 该算法允许megaflow条目仅与高阶位匹配,足以区分具有ACL的主机的流量。
我们最终还为L4传输采用了基于端口号的前缀跟踪。 与IP ACL类似,这可以防止与特定传输端口匹配的高优先级ACL(例如,阻止SMTP)强制所有megaflow匹配整个传输端口字段,这也是将megaflow缓存减少到微流缓存[32]。
因为是先做prefix tracking,后查megaflow cache,所以,对于ACL来说在prefix tracking阶段就可以匹配flow过滤报文了。
5.5 分类器分区(Classifier Partitioning)
通过跳过不可能匹配的元组可以进一步减少元组空间搜索次数。OpenFlow支持在分类器处理包期间,设置和匹配元数据字段。Open vSwitch根据特定的元数据字段对分类器进行分区。 如果该字段中的当前值与特定元组中的任何值不匹配,则该元组将被完全跳过。
尽管Open vSwitch没有像传统交换机那样的固定管道,但NVP经常会将分类器中的每个查找配置为管道中的一个阶段。这些阶段匹配固定数量的字段,类似于元组。通过将流水线阶段的数字指示符存储到专门的元数据字段中,NVP向分类器提供提示以有效地仅查看相关的元组。
6 缓存失效(Cache Invalidation)
缓存的另一面是管理缓存的复杂性。在Open vSwitch中,由于多种原因,缓存可能需要更新。 最明显的是,控制器可以更改OpenFlow流表。OpenFlow还指定交换机应对各种事件作出的改变,例如OpenFlow“组”行为可取决于是否在网络接口上检测到 carrier 。重新配置打开或关闭功能,添加或删除端口等可能会影响数据包处理。 诸如CFM [10]或BFD [14]之类的连通性检测协议或者用于环路检测和避免(例如(快速)生成树协议)的协议可影响行为。最后,一些OpenFlow操作和Open vSwitch扩展会基于网络状态(例如,基于MAC学习)来改变行为。
理想情况下,Open vSwitch可以精确识别需要为响应某些事件而改变的巨型流。 对于某些事件,这很简单。 例如,当MAC学习的Open vSwitch实现检测到MAC地址已从一个端口移到另一个端口时,使用该MAC的datapath流就是需要更新的那些流。 但是在其他情况下,OpenFlow模型的普遍性使得难以精确识别。 一个例子是向OpenFlow表添加新流。 与优先级小于新流优先级的OpenFlow表中的流匹配的任何megaflow现在都可能表现出不同的行为,但我们不知道如何有效地(在时间和空间上)精确地识别这些流(Header space analysis [16]提供了识别流程的代数,但在这种情况下进行有效的在线分析的可行性(如[15])仍然是一个悬而未决的问题)。 长时间的OpenFlow流表查找序列进一步恶化了问题。 我们的结论是,在一般情况下要求精度是不切实际的。
因此,早期版本的Open vSwitch将dtapath flow可能需要的更改分为了2个组。
对于第一组,由于其影响过于广泛而无法准确识别所需要的更改,Open vSwitch必须检查每个datapath flow以了解可能的更改。 每个流程都必须以与最初构建相同的方式通过OpenFlow流程表,然后将生成的action与当前安装在datapath中的action进行比较。 如果有很多datapath流,这可能会非常耗时,但是我们并未发现这在实践中会成为问题,这可能是因为只有当系统实际上网络负载较高时,才会有大量的datapath流,而此时在网络处理上使用更多CPU是合理的。 真正的问题在于,因为Open vSwitch是单线程的,所以对datapath flow重新检查会造成阻塞,阻塞那些没有匹配任何datapath flow的包的新建flow操作。 这为这些数据包的流设置增加了高延迟,flow建立的延迟时间变化会很大,也限制了整体流设置速率。 因此,从2.0版本开始,Open vSwitch将datapath中安装的流缓存的最大数量限制为大约1,000,在某些优化之后将其增加到2,500,以最大限度地减少这些问题。
第二组包括对datapath flow的影响可以被缩小,例如MAC学习表的变化。
早期版本的Open vSwitch使用称为tags的技术以优化的方式实现了这些功能。
ovs给每个变化以后需要megaflow更新的属性赋予了一个tag。
此外,每个megaflow都与其actions所依赖的所有属性对应的标签相关联,例如,如果action将数据包输出到端口x(因为学习到的数据包的目标MAC是在该端口上),则megaflow与该标签关联。 稍后,如果学习到的MAC端口发生更改,则Open vSwitch会将 tag 添加到一组累积更改的tags集里。 稍后, Open vSwitch 批量扫描megaflow表以查找 tags集中包括该已更改的tag的megaflow,并检查其操作是否需要更新。
随着时间的推移,随着控制器变得越来越复杂,flow table变得更加复杂,并且随着Open vSwitch添加了更多基于网络状态而行为发生变化的操作,每个dadtapath流程都会标记越来越多的标记。 我们将标签实现为Bloom filter[2],这意味着每个额外的标签都会导致更多的“误报”以进行重新验证,所以现在大部分甚至全部流程在任何状态发生更改时都需要进行检查。
由于标签是我们寻求最小化流量建立延迟的方法之一,因此我们现在寻找其他方法。 在Open vSwitch 2.0中,为此,我们将用户空间划分为多个线程。我们将流设置分解成单独的线程,以便它不必等待重新验证。 然而,数据通路流量的 eviction 仍然是单线程的,并且无法跟上设置流程的多个线程。 但是,在大流量设置负载下, eviction 可能发生的速率非常关键,因为用户空间必须能够尽快从datapath中删除流,因为它可以安装新流,否则datapath缓存将快速填满。 因此,在Open vSwitch 2.1中,我们引入了多个用于缓存重新验证的专用线程,这使我们可以扩展重新评估性能,以匹配流设置性能,并将内核缓存最大大小增加到大约200,000个条目。实际的最大值是动态调整的,以确保总重新验证时间保持在1秒以下,以限制旧表项可以保留在高速缓存中的时间量。
打开vSwitch用户空间定期(大约每秒一次)轮询内核模块以获取每个流的数据包和字节计数器,从而获得datapath高速缓存统计信息。 datapath流量统计的核心用途是确定哪些datapath流是有用的,应该保留在内核中,哪些不处理大量数据包,应该被驱逐。 快达到表格的最大大小时,流程将保留在datapath中,直到它们超过一段闲置时间(时间可配置,现在默认为10秒)。 (超过最大大小以后,Open vSwitch会放弃此空闲时间来强制缩小表。) 定期轮询内核以获得每流统计信息的线程也使用这些统计信息来实现OpenFlow的每个流分组和字节计数统计信息以及流空闲超时功能。 这意味着OpenFlow统计数据本身只是定期更新。
以上描述了用户空间如何使datapath的megaflow缓存失效。 第一级的微流高速缓存的维护(第四节讨论)要简单得多。 微流缓存条目仅仅是第一个哈希表的提示,用于在通用元组空间搜索(TSS)中进行搜索。 因此,当数据包第一次与其匹配时,会检测并纠正一个陈旧的微流缓存条目。 微流缓存具有固定的最大尺寸,新微流代替旧微流,因此不需要定期刷新旧条目。 为了简单起见,我们使用伪随机替换策略,并且发现它在实践中是有效的。
7 Evaluation
以下各节将分析生产和微型基准测试中的Open vSwitch性能。
7.1 Performance in Production
我们在Rackspace运营的大型商用多租户数据中心中检查了24小时来自管理程序的Open vSwitch性能数据。 我们的数据集包含来自运行Open vSwitch的超过1,000个Hypervisor每10分钟轮询一次的统计信息,以在网络虚拟化设置中提供混合租户工作负载。
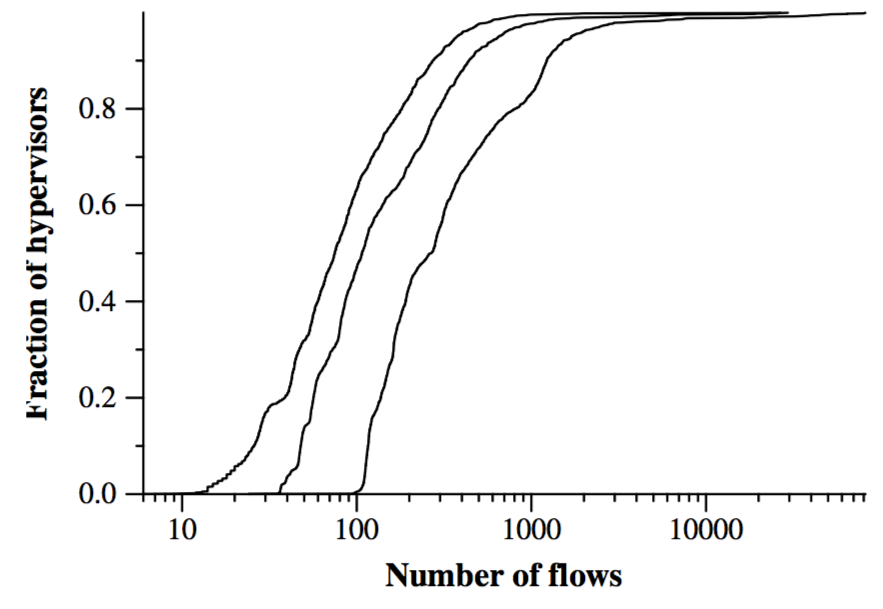
Cache sizes. active megaflow的数量为我们提供了Open vSwitch所管理的实际megaflow高速缓存大小的说明。 在图4中,我们显示了观测期间最小,平均和最大计数的CDF。 这些图显示在实践中小型megaflow缓存足够了:50%的hypervisors的平均流量为107或更少。 最大流量的第99位仍然只有7033流量。 对于此环境中的管理程序,Open vSwitch用户空间可以维护足够大的内核缓存。 (使用最新的Open vSwitch主流版本,内核流量限制设置为200,000个条目。)
Cache hit rates.
略
7.2 Caching Microbenchmarks
略
TODO==>
8 Ongoing, Future, and Related Work
8.1 Stateful Packet Processing
8.2 Userspace Networking
8.3 Hardware Offloading
8.4 Related Work
9 Conclusion
Subscribe via RSS