不要开启tcp_tw_recycle
by 伊布
TL;DR:
不要开启net/ipv4/tcp_tw_recycle
问题描述
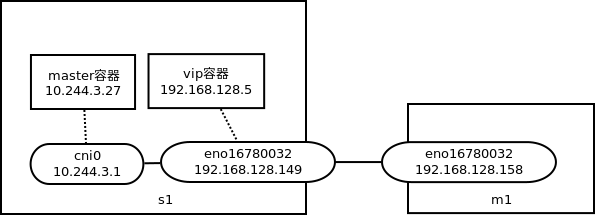
我们把Greenplum搬到了kubernetes上面。Greenplum主控分为master和standby两个容器,分别跑在2个物理机器上,容器网络为NAT(flannel);为了方便用户访问,我们为每个租户分配了一个virtual ip(物理机器网段),该地址由keepalived管理,具体实现上我们使用了kube-keepalived-vip,它也以容器的方式跑在kubernetes上,宿主机网络(因为要向宿主机下发virtual ip),对keepalived本身做了封装:通过configmap传递virtual ip和real server(即master容器的ip地址,rmt50-vip-svc的endpoint),并生成keepalived的配置文件,然后启动keepalived。keepalived会向内核下发lvs规则,将到virtual ip + 5432(192.168.128.5 5432)的报文走NAT转发给master容器(10.244.3.27 5432)。
configmap:
apiVersion: v1
data:
192.168.128.5: default/rmt50-vip-svc
kind: ConfigMap
具体keepalived.conf:
vrrp_instance vips {
state BACKUP
interface eno16780032
virtual_router_id 28
priority 100
nopreempt
advert_int 1
track_interface {
eno16780032
}
virtual_ipaddress {
192.168.128.5
}
}
# Service: default/rmt50-vip
virtual_server 192.168.128.5 5432 {
delay_loop 5
lvs_sched wlc
lvs_method NAT
persistence_timeout 1800
protocol TCP
real_server 10.244.3.27 5432 {
weight 1
TCP_CHECK {
connect_port 5432
connect_timeout 3
retry 1
delay_before_retry 3
}
}
}
该租户各个容器的地址如下。其中rmt50-master为master容器,rmt50-standby是standby容器,rmt50-vip为vip容器。
kubectl get pods -o wide|grep rmt50
rmt50-master 1/1 Running 0 2d 10.244.3.27 s2.adb.g1.com
rmt50-standby 1/1 Running 0 2d 10.244.1.250 m2.adb.g1.com
rmt50-vip 1/1 Running 5 2d 192.168.128.149 s2.adb.g1.com
但实际使用时,发现psql连接virtual ip(192.168.128.5)有一定概率会失败,服务器反馈端口不可达;查看kube-keepalived-vip容器(下面简称vip容器)的日志,发现是TCP_CHECK检测real_server超时后,将real_server从内核lvs表项中删除了(通过ipvsadm -l查看)。
一开始我以为是网络抖动,所以把connection_timeout, retry都调大了一点(retry 1确实有点太严苛了),之后的确有所改善,但问题并没有根除,如果从另一物理机器(m1)和vip容器上同时去频繁psql连接virtual ip,基本上几分钟就可以复现出来。
定位过程
怀疑点1:网络
出现问题时,docker exec进入vip容器,发现ping master容器正常,说明从vip容器到master容器的网络是正常的。由于vip容器和master容器都在同一个物理机器上(s1),只是vip容器在宿主机网络上,而master容器在flannel网络内;由于宿主机网络有所有的路由,因此从vip容器出来的报文,直接走cni0转发即可,源地址使用cni0的地址,一般来说不太会出问题。
怀疑点2:postgre进程故障
在master容器上tcpdump抓包,可以看到vip 容器发过来的syn报文,但是master容器并没有应答,导致syn报文一直重传。如果postgre进程跑飞了会不会造成这个现象呢?在出问题的时候,我strace -p pid了下postgre进程,看到一直在select,说明内核没有上报新socket事件。
其实,根本就不应该怀疑postgre进程。从抓包看到只有收到syn没有应答syn+ack,就可以肯定跟用户态的postgre进程无关了:tcp三次握手完全是内核完成的,只有3次握手结束,内核才会给用户态进程上报事件;用户态最多就是不响应该事件,但不会造成不应答syn+ack。
怀疑点3:内核丢包
只有这种可能了。linux内核调试起来比较麻烦,不过可以通过proc来看一些统计信息。
cat /proc/net/netstat
TcpExt: SyncookiesSent SyncookiesRecv SyncookiesFailed EmbryonicRsts PruneCalled RcvPruned OfoPruned OutOfWindowIcmps LockDroppedIcmps ArpFilter TW TWRecycled TWKilled PAWSPassive PAWSActive PAWSEstab DelayedACKs DelayedACKLocked DelayedACKLost ListenOverflows ListenDrops TCPPrequeued TCPDirectCopyFromBacklog TCPDirectCopyFromPrequeue TCPPrequeueDropped TCPHPHits TCPHPHitsToUser TCPPureAcks TCPHPAcks TCPRenoRecovery TCPSackRecovery TCPSACKReneging TCPFACKReorder TCPSACKReorder TCPRenoReorder TCPTSReorder TCPFullUndo TCPPartialUndo TCPDSACKUndo TCPLossUndo TCPLostRetransmit TCPRenoFailures TCPSackFailures TCPLossFailures TCPFastRetrans TCPForwardRetrans TCPSlowStartRetrans TCPTimeouts TCPLossProbes TCPLossProbeRecovery TCPRenoRecoveryFail TCPSackRecoveryFail TCPSchedulerFailed TCPRcvCollapsed TCPDSACKOldSent TCPDSACKOfoSent TCPDSACKRecv TCPDSACKOfoRecv TCPAbortOnData TCPAbortOnClose TCPAbortOnMemory TCPAbortOnTimeout TCPAbortOnLinger TCPAbortFailed TCPMemoryPressures TCPSACKDiscard TCPDSACKIgnoredOld TCPDSACKIgnoredNoUndo TCPSpuriousRTOs TCPMD5NotFound TCPMD5Unexpected TCPSackShifted TCPSackMerged TCPSackShiftFallback TCPBacklogDrop TCPMinTTLDrop TCPDeferAcceptDrop IPReversePathFilter TCPTimeWaitOverflow TCPReqQFullDoCookies TCPReqQFullDrop TCPRetransFail TCPRcvCoalesce TCPOFOQueue TCPOFODrop TCPOFOMerge TCPChallengeACK TCPSYNChallenge TCPFastOpenActive TCPFastOpenActiveFail TCPFastOpenPassive TCPFastOpenPassiveFail TCPFastOpenListenOverflow TCPFastOpenCookieReqd TCPSpuriousRtxHostQueues BusyPollRxPackets TCPAutoCorking TCPFromZeroWindowAdv TCPToZeroWindowAdv TCPWantZeroWindowAdv TCPSynRetrans TCPOrigDataSent TCPHystartTrainDetect TCPHystartTrainCwnd TCPHystartDelayDetect TCPHystartDelayCwnd TCPACKSkippedSynRecv TCPACKSkippedPAWS TCPACKSkippedSeq TCPACKSkippedFinWait2 TCPACKSkippedTimeWait TCPACKSkippedChallenge
TcpExt: 0 0 118 0 0 0 0 0 1 0 94979 0 960494 0 0 906 343087 1119 5435 0 0 432477 9530 21215128 0 7057137 7 2736264 2582522 0 4 0 1 2 0 0 0 0 6 317 0 0 5 0 92 0 23 1992 1464 713 0 0 4 0 5450 62 1557 0 293509 80 0 12 0 0 0 0 0 782 49 0 0 0 0 171 0 0 0 0 0 0 0 2 1743889 11075 0 69 7 3 0 0 0 0 0 0 174 0 303158 542 542 3641 3021 21292349 27 749 0 0 0 0 0 0 0 0
IpExt: InNoRoutes InTruncatedPkts InMcastPkts OutMcastPkts InBcastPkts OutBcastPkts InOctets OutOctets InMcastOctets OutMcastOctets InBcastOctets OutBcastOctets InCsumErrors InNoECTPkts InECT1Pkts InECT0Pkts InCEPkts
IpExt: 3 0 4802567 1188058 6661 0 57132122839 92642737581 189351200 38019672 2189009 0 0 85932763 0 0 0
非常友好的统计信息!
回头还是用go写个小工具format下netstat,这个真的太难看了。我用atom把netstat竖排了下,发现有个ListenDrops计数在出现问题的时候会有变大。呵呵呵,坏人抓到了。
这里可以用我写的netproc来观察net计数的变化,还是比较友好的!
来看内核的这个计数是干啥的。
ListenDrops计数对应内核的LINUX_MIB_LISTENDROPS,走读下代码,可以看到有很多情况该计数会增加,为了区分不同情况,内核会在增加LINUX_MIB_LISTENDROPS的同时增加其他的计数。不慌,我们再看下netstat的信息,有没有发现PAWSPassive的计数跟ListenDrops是一致的?是不是巧合呢?没关系,我们再重复一把,看看netstat的变化。
果然还是一致的。
两次netstat的信息:
PAWSPassive 3565 3858
ListenDrops 3565 3858
PAWSPassive对应内核的LINUX_MIB_PAWSPASSIVEREJECTED,它只有一种情况下会出现:
tcp_ipv4.c/tcp_v4_conn_request:
int tcp_v4_conn_request(struct sock *sk, struct sk_buff *skb)
/* VJ's idea. We save last timestamp seen
* from the destination in peer table, when entering
* state TIME-WAIT, and check against it before
* accepting new connection request.
*
* If "isn" is not zero, this request hit alive
* timewait bucket, so that all the necessary checks
* are made in the function processing timewait state.
*/
if (tmp_opt.saw_tstamp &&
tcp_death_row.sysctl_tw_recycle &&
(dst = inet_csk_route_req(sk, &fl4, req)) != NULL &&
fl4.daddr == saddr) {
if (!tcp_peer_is_proven(req, dst, true)) {
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_PAWSPASSIVEREJECTED);
goto drop_and_release;
}
}
drop_and_release:
dst_release(dst);
drop_and_free:
reqsk_free(req);
drop:
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_LISTENDROPS);
return 0;
net/ipv4/tcp_metrics.c:
bool tcp_peer_is_proven(struct request_sock *req, struct dst_entry *dst, bool paws_check)
{
struct tcp_metrics_block *tm;
bool ret;
if (!dst)
return false;
rcu_read_lock();
tm = __tcp_get_metrics_req(req, dst);
if (paws_check) {
if (tm &&
(u32)get_seconds() - tm->tcpm_ts_stamp < TCP_PAWS_MSL &&
(s32)(tm->tcpm_ts - req->ts_recent) > TCP_PAWS_WINDOW)
ret = false;
else
ret = true;
}
内核版本为3.10。
简单来说,当开启了tcp_tw_recycle时,kernel会记录每个peer的最后一个报文的时戳,如果记录的该时戳仍然有效(距离当前时间小于TCP_PAWS_MSL),并且新收到的syn报文的时戳,比kernel记录的该peer的时戳还要小(换句话说,时光倒流了),那么就认为新收到的syn报文是有问题的(比如是某个在网络上兜兜转转了很久才到目的地址的syn),从而drop之。
所以我们看到的现象就是,内核收到了新的syn报文,但只是默默drop了(没什么好处理方法,回RST可能误伤),所以造成了psql连接超时。
解决方法
只要将net.ipv4.tcp_tw_recycle恢复为默认值0即可。
深入理解
TIME_WAIT是干啥的
先祭出tcp状态机迁移图。做协议栈的都要能默写啊!
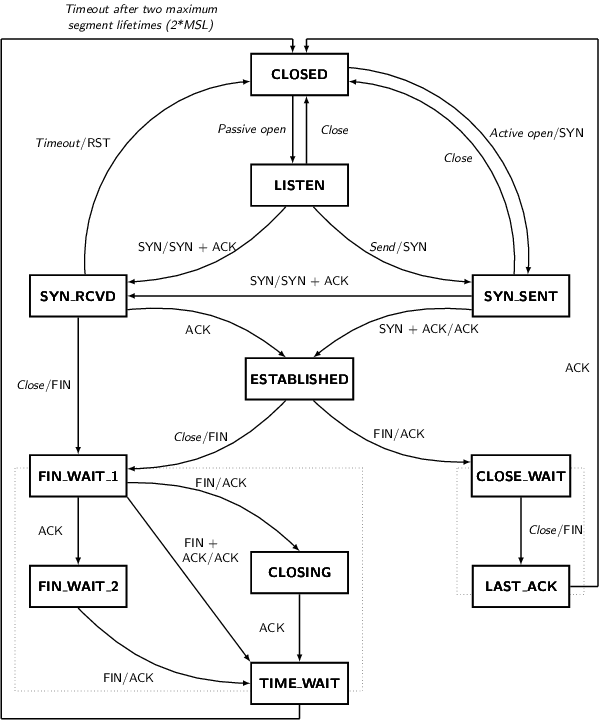
只有主动关闭连接的一方,才会转移到TIME_WAIT。
TIME_WAIT的主要目的有2个:
避免误收延迟到达的报文
如下图,由于TIME_WAIT的时间被缩短了,造成新建的连接收到了之前延迟到达的报文(5元组是匹配的)。

保证对端已经关闭了连接
如下图,由于TIME_WAIT的时间被缩短了,对端还处于LAST_ACK状态,本端发送的syn报文被直接RST掉了。

为什么Greenplum会开启tcp_tw_recycle
为什么内核会开启net.ipv4.tcp_tw_recycle=1呢?网络上有很多资料建议繁忙的服务器开启这个sysctl,Greenplum也在其官网的资料Linux System Settings里提到,linux的/etc/sysctl.conf中应设置net.ipv4.tcp_tw_recycle=1。
开启tcp_tw_recycle的目的是为了减少TIME_WAIT状态的socket连接,从而减少内存、cpu的使用,因为TIME_WAIT状态的socket会快速释放;也可以提高并发连接的规格,因为客户端可以使用的端口号更多了。对比下没有开启recycle的情况,若服务端先关闭连接,socket会停留在TIME_WAIT状态的时间是1个TCP_PAWS_MSL(在linux上是1分钟),在此时间内,客户端不能再使用刚刚用过的源端口号,否则服务端会直接RST之。
看上去很美好。
为什么不要开启tcp_tw_recycle
但人算不如天算,当网络中存在NAT的情况下,开启tcp_tw_recycle会引起上述syn报文被丢弃的问题。我们来看下为什么。
从前面问题定位的过程可以发现,tcp_tw_recycle能够运转,其基础是tcp报文中需要带TIMESTAMP时戳选项。要了解tcp_tw_recycle,必然要先了解下tcp时戳选项。TCP timestamp这篇文章中详细的讲解了时戳,建议先跳转过去看看。
简单来说,TCP协议中有一个很重要的概念:RTO(Retransmission TimeOut),重传超时时间,RTO是根据RTT(Round Trip Time)来动态调整的。但如何测量RTT呢?
一个办法是计算报文发送时间和对端ack确认的时间差,作为RTT。但由于报文重传、SACK等原因,这样计算出来的RTO可能会偏大,因此一般会选择没有重传的报文来计算。
另一个办法就是使用TIMESTAMP选项。
- 发送方在发送数据时,将一个timestamp(表示发送时间)放在包里面
- 接收方在收到数据包后,在对应的ACK包中将收到的timestamp返回给发送方(echo back)
- 发送发收到ACK包后,用当前时刻now - ACK包中的timestamp就能得到准确的RTT
时戳的值,在linux上是这样定义的:
include/net/tcp.h
/* TCP timestamps are only 32-bits, this causes a slight
* complication on 64-bit systems since we store a snapshot
* of jiffies in the buffer control blocks below. We decided
* to use only the low 32-bits of jiffies and hide the ugly
* casts with the following macro.
*/
#define tcp_time_stamp ((__u32)(jiffies))
jiffies即系统从开机到现在的时钟中断次数。
回到tcp_tw_recycle上来。我们来看下tcp_peer_is_proven这个函数中是怎么判断是否应该丢弃该syn报文的。
if (tm &&
(u32)get_seconds() - tm->tcpm_ts_stamp < TCP_PAWS_MSL &&
(s32)(tm->tcpm_ts - req->ts_recent) > TCP_PAWS_WINDOW) //here
ret = false;
else
ret = true;
只要新包的时戳比上次看到的时戳小,就判断报文有问题。可见,同一个peer的时戳,必须要线性增长,否则判断会出错。显然,一般情况下对于同一个客户端,”时戳线性增长”这个前提是满足的,但如果客户端在NAT之后呢?
我们在家里访问外部服务器的时候,家里可能有多台终端,其地址可能是192.168.1.100, 192.168.1.101,但在从家庭路由器出去的时候,会做一次SNAT,将报文的源地址替换为运营商给我们分配的公网地址。对于服务器来说,只能看到该公网地址。但由于2台终端开机的时间不一样,其报文中的TIMESTAMP选项值也不一样。因此,如果192.168.1.100的开机时间比192.168.1.101早,可能会出现192.168.1.100的连接关闭以后,192.168.1.101无法立即建立连接,因为后收到的syn报文的TIME_STAMP的值更小。在服务端来看,时间不可能倒流,那么新来的syn报文可能是个迟到的家伙,因此必然会被drop,192.168.1.101只能等一会才能建立连接(TCP_PAWS_MSL之后)。
如果192.168.1.100在频繁的连接建立、断开,192.168.1.101可能很久都无法连接的上。
特殊国情
但我们的环境中,并不符合上述客户端在NAT里面的情况,而是反过来:master容器在NAT里面。
客户端访问virtual ip时,内核会做一次DNAT,将报文目的地址virtual ip转为master的ip,源地址不变。如果之后报文直接走cni0进入master容器,其实不会出现上面的问题:报文源地址是不同的。但由于kubernetes的缘故,报文在POSTROUTING阶段,还是会做一次SNAT(此处应该给生哥掌声):
Chain POSTROUTING (policy ACCEPT 6 packets, 360 bytes)
pkts bytes target prot opt in out source destination
6351K 563M KUBE-POSTROUTING all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes postrouting rules */
0 0 MASQUERADE all -- * !docker0 172.17.0.0/16 0.0.0.0/0
2601K 177M RETURN all -- * * 10.244.0.0/16 10.244.0.0/16
102K 6466K MASQUERADE all -- * * 10.244.0.0/16 !224.0.0.0/4
1248K 86M MASQUERADE all -- * * !10.244.0.0/16 10.244.0.0/16
即:若报文的源地址和目的地址一个是10.244.0.0/16网段,一个不是,则走MASQUERADE,即做一次SNAT。MASQUERADE表示源地址不静态指定,而是动态选择。
因此,从m1上发出的psql请求,在经过lvs的一次DNAT和POSTROUTING阶段的一次SNAT之后,报文的源地址和目的地址,从192.168.128.158->192.168.128.5,变为了10.244.3.1->10.244.3.27;而从vip容器发出的psql请求,其源地址和目的地址就是10.244.3.1->10.244.3.27。
悲剧就发生了。
由于vip容器所在的机器启动时间要晚一点,因此受害者总是它,也就是我们一开始所描述的vip容器去psql连接master容器超时,但从m1上访问总是没问题的现象。
btw:上面的lvs+iptables实现了FULLNAT的效果,可以不给内核打阿里的补丁。
总结
tcp_tw_recycle这个选项在内核的文档里说明的比较含糊,但是有一句警告:
Enable fast recycling TIME-WAIT sockets. Default value is 0. It should not be changed without advice/request of technical experts.
意思就是:特殊勤务,请勿靠近。
不过man 7 tcp里倒是挺干脆的提示:
Enable fast recycling of TIME_WAIT sockets. Enabling this option is not recommended since this causes problems when working with NAT (Network Address Translation).
ref:
Subscribe via RSS