在kubernetes上使用flume TAILDIR收集日志到HDFS上
by 伊布
需求分析
我们的应用以前直接跑在物理机上,应用日志使用flume ng 的exec方式(即tail -F)收集后,写到HDFS上。如下图:
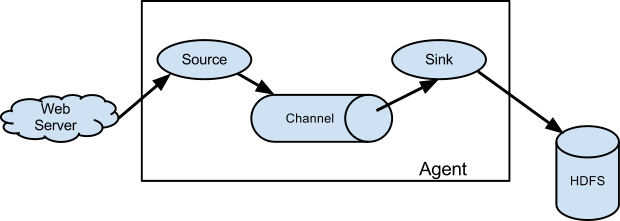
在flume.conf中定义sources、channels、sinks:
agent1.sources = source1
agent1.channels = ch1
agent1.sinks = sink1
agent1.sources.source1.type = exec
agent1.sources.source1.shell = /bin/bash -c
agent1.sources.source1.command = tail -n +0 -F /log/LOG_FILE_NAME
agent1.sources.source1.channels = ch1
agent1.channels.ch1.type = memory
agent1.channels.ch1.capacity = 10000
agent1.channels.ch1.transactionCapacity = 1000
agent1.sinks.sink1.channel = ch1
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = hdfs://dtyundun/logs/flume/SERVICE_NAME/
agent1.sinks.sink1.hdfs.writeFormat = Text
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.rollSize = 134217728
agent1.sinks.sink1.hdfs.rollCount = 0
agent1.sinks.sink1.hdfs.rollInterval = 0
agent1.sinks.sink1.hdfs.batchSize = 1000
#agent1.sinks.sink1.hdfs.maxOpenFiles=1
agent1.sinks.sink1.hdfs.filePrefix = FILENAME
agent1.sinks.sink1.hdfs.fileSuffix=.out
agent1.sinks.sink1.hdfs.threadsPoolSize = 10
hdfs sink的参数说明可以看官方说明。需要注意由于HDFS一般会设置blocksize为128MB或者64MB,所以不要在文件很小的时候就roll,否则会产生大量的小文件,非常浪费HDFS的空间。我这里配置了rollSize为128MB,而rollCount(Number of events written to file before it rolled),rollInterval(Number of seconds to wait before rolling current file)都配置为0,即是否roll只看rollSize,这样只有文件到了128MB才会生成新文件。
但是,当应用上了k8s以后呢?
一个思路是走虚拟机的套路,也就是在每个应用容器里跑一个flume agent。但flume agent要求Java环境,跟着应用镜像的话,太大了,而且对应用开发者来说也很不爽,我打包个镜像你还要我装个小尾巴。
另一个思路是,应用向kubernetes申请一个hostPath类型的volume,应用只要把日志存到这个volume里去就行了;k8s在宿主机上跑flume agent监控hostPath所在的固定目录,并把文件传到HDFS上去。这对应用开发者来说很友好,不需要care任何日志收集的事情(要存HDFS也好,要ELK也好,全都由k8s集群管理员负责)。看上去这个思路不错,ELK用来做日志解析据说也很方便。只是在宿主机上装应用不太方便,再上一套ELK也有点重。
还有一个思路,给应用容器搭配一个僚机(side car),这个容器里只跑flume ng;将应用的日志volume挂载到flume ng容器里,让flume采集以后写到HDFS上。不侵入应用镜像,但要求应用上k8s的时候,编排文件里带上flume ng。
以上三个方案,第一个不靠谱,第二个最合适,不过ELK略微有点重,我比较喜欢第三个方案。
实现细节
flume ng支持的source类型很多,我们之前使用的是exec类型,但在k8s上不好使。为什么呢?
exec的数据来源其实就是tail -F xxx.log(一行一个event),也就是说,xxx.log这个文件必须存在,否则flume ng认为源不存在,采集失败。当然可以在启动flume之前检测下文件是否存在,但灵活性很差:比如应用写的日志不止一个文件,比如应用可能跑着跑着突然生成一个新日志文件。
回过头来看,在k8s上,flume ng实际上是一个类框架的容器,它不应该对应用产生日志的行为做太多限制,只要是输出到应用指定volume的日志,无条件接受就行了。
flume还支持 Spooling Directory Source 类型,可以指定一个目录,看上去符合我们的要求,但其实这娃的行为是这样的:
- If a file is written to after being placed into the spooling directory, Flume will print an error to its log file and stop processing.
- If a file name is reused at a later time, Flume will print an error to its log file and stop processing.
简单来说,Spooling Directory Source类型就是个一锤子买卖,文件放我这个目录我会给你传到HDFS上,但你就别想再动了,原始文件我也会改名加后缀.COMPLETED,不能再次添加同样名字的文件,当然也无法再修改这个文件了。
看到这里,发现了没,其实我们需要的,就是Exec Source + Spooling Directory Source的合体呀!
flume还是贴心的,目前的1.7.0版本推出了一个新的Source类型,叫做 Taildir Source。只要指定一个目录,flume会把新增的文件、已有文件新append的内容,都tail过去。
是不是好棒棒?
下面是配置:
agent1.sources.source1.type = TAILDIR
agent1.sources.source1.filegroups = f1
agent1.sources.source1.filegroups.f1 = /log/.*
是不是好棒棒?
flume.conf解决了以后,只要再给 flume 打包Docker镜像就可以了。值得注意的是,由于flume agent镜像需要写HDFS,所以如果只在Docker里加了flume自己的话,会报ClassNotFound错误。一个做法是把Docker宿主机上的目录挂载进去然后不管3721全部拷贝到/flume/lib/下,但稍嫌粗暴。实际上需要的jar包并不是很多,我列在了下面(我把jar包放到了s3上,docker build的时候去取就好了)。
RUN s3cmd get s3://flume/hadoop-auth-2.7.1.2.4.2.0-258.jar /flume/lib && \
s3cmd get s3://flume/hadoop-common-2.7.1.2.4.2.0-258.jar /flume/lib && \
s3cmd get s3://flume/hadoop-hdfs-2.7.1.2.4.2.0-258.jar /flume/lib && \
s3cmd get s3://flume/commons-configuration-1.6.jar /flume/lib && \
s3cmd get s3://flume/hadoop-mapreduce-client-core-2.7.1.2.4.2.0-258.jar /flume/lib && \
s3cmd get s3://flume/htrace-core-3.1.0-incubating.jar /flume/lib && \
s3cmd get s3://flume/commons-io-2.4.jar /flume/lib
另外就是注意要用hdfs用户去启动flume agent,因为需要写HDFS。
flume agent的Docker镜像ready了以后,剩下的就是编辑应用的编排文件。下面直接给一个centos的例子。
apiVersion: v1
kind: ReplicationController
metadata:
name: centos7-pod
spec:
replicas: 1
template:
metadata:
labels:
unit: centos7-pod
spec:
containers:
- name: flume-agent
image: docker.datastart.cn/datastart/flume:1.7.0
imagePullPolicy: Always
volumeMounts:
- mountPath: /log/
name: cache-volume
- mountPath: /hadoop-conf/
name: hadoop-conf
env:
- name: SERVICE_NAME
value: centos
- resources:
limits:
cpu: 1
image: docker.datastart.cn/datastart/centos:7.2.1511
name: centos7-node1
command: ["/bin/sh", "-c", "sleep 36000"]
volumeMounts:
- mountPath: /var/log/
name: cache-volume
volumes:
- name: hadoop-conf
configMap:
name: hadoop-conf
- name: cache-volume
emptyDir: {}
应用(centos)和flume 沟通的桥梁,就是那个cache-volume。flume会将centos在/var/log下生成的所有日志都采集上传到HDFS上。注意hadoop-conf这个volume,因为要写HDFS,所以flume需要core-site.xml和hdfs-site.xml,这两个文件在不同集群里是不同的,因此我们在每个集群里都创建了一个名为hadoop-conf的configmap,其内容为/etc/hadoop/conf这个目录下的所有文件。对于flume容器来说,只需要将这个configmap挂载以后拷贝走core-site.xml和hdfs-site.xml两个文件到flume conf目录即可,其他的不需要。
以上就是在kubernetes上使用flume TAILDIR收集日志到HDFS上的方案细节,基本上能够满足我们的需求。
不过有一个不爽的地方是,我没办法把不同的文件的原始名字保存到HDFS上,如果你有办法请留言。
update:2017-05-19
TAILDIR是支持将flume src的多个文件,按照文件的原始名字存储到HDFS上的,之前的配置有问题。
| Property Name | Default | Description |
|---|---|---|
| fileHeader | false | Whether to add a header storing the absolute path filename. |
| fileHeaderKey | file | Header key to use when appending absolute path filename to event header. |
fileHeader设置为true以后,会将文件名字带到event的header里去,这样hdfs sink拿到event就知道文件的名字了。hdfs sink使用%{file}取到filename以后传给hdfs.filePrefix即可。
具体配置如下。
agent1.sources.avro-source1.fileHeader = true
agent1.sources.avro-source1.fileHeaderKey = file
agent1.sinks.log-sink1.hdfs.filePrefix = %{file}-%Y-%m-%d
贴下过程日志。HDFS上文件的名字保留了原始文件的名字。
2017-05-19 13:29:15,280 (PollableSourceRunner-TaildirSource-avro-source1) [INFO - org.apache.flume.source.taildir.ReliableTaildirEventReader.openFile(ReliableTaildirEventReader.java:283)] Opening file: /log/sososo.xxx.23-222-xa.log, inode: 402084, pos: 0
2017-05-19 13:29:15,282 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.HDFSDataStream.configure(HDFSDataStream.java:57)] Serializer = TEXT, UseRawLocalFileSystem = false
2017-05-19 13:29:15,316 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:231)] Creating hdfs://logs/flume/datastart/sososo.xxx.23-222-xa.log-2017-05-19.1495171755283.out.tmp
Subscribe via RSS