kubernets的网络插件:flannel
by 伊布
kubernets的网络,从设计上来讲是“扁平、直接”的,即要求:
- 所有容器可以不使用NAT技术就可以与其他容器通信
- 所有节点(物理机 虚拟机 容器)都可以不使用NAT同容器通信
- 容器看到的IP地址和别的机器看到的IP是一致的
docker的网络方案
docker的网络支持如下四种:
- none
- host,与宿主机共享,占用宿主机资源
- container,使用某容器的namespace,例如k8s的同一pod内的各个容器
- bridge,挂到网桥docker0上,走iptables做NAT
实际上还有一种方法:先以none的方式run起来容器,然后使用pipework为容器增加一个veth网卡,该veth的另一端挂到新建的网桥br0上;再将宿主机的物理网卡挂到该网桥br0上:
[容器内eth0]--veth--br0--en0-->
需要注意这种方法与bridge的不同。docker0的网段是172.17.0.1/16,当bridge模式时,容器的ip地址均为此网段下的,报文是走NAT出去的。但pipework自定义网络时,br0、[eth0]均与宿主机的en0同一网段,报文走网桥转发出去。
docker的网络能否满足需求呢?
bridge模式下,不同物理机的容器ip是完全的平行空间,可能相同,不能满足k8s扁平的要求;pipework方式能够满足k8s的要求,但是需要为每个容器都指定ip地址,比较啰嗦。
k8s的flannel模式
k8s本身并不提供网络方案,而是交给flannel,ovs等add-on来处理。这里只对flannel做说明。
flannel模式原理
flannel是一种over-lay网络。简单来说,over-lay即报文在进入实际物理网络之前,会经过一层UDP封装,作为payload到达对端;对端拿到UDP报文后解包,得到真实的用户报文后,再转到真实的接收方。

以绿色线的一个具体报文来说:
1、Pod内的一个容器使用pod的网络namespace,发送报文;该网络namespace上的网卡类型为veth,其pair网卡为宿主机网络namespace空间上的veth网卡veth0。veth是一种类似管道的网络设备,总是成对出现,报文从一端的veth网卡发送后,另一端的veth网卡会收到该报文。通常容器、虚拟机,会创建一对veth网卡,并将其中一端加到自己的namespace中。因此,宿主机的veth0网卡会收到容器发出的报文。
2、veth0拿到后,由于目的地址10.1.20.x与veth不在同一网段,因此会将报文交给网桥来转发。官方图示为docker0,但出于网络地址规划的原因,实际在k8s上会新建一个cni0网桥,cni0网桥负责本node容器的ip分配(24位掩码)。 这里有一个问题:各个node都有自己的cni0网桥,怎么保证地址不会分配重复呢?这里就是靠flannel了,flannel会根据全局统一的etcd来为每个node分配全集群唯一的网段,避免地址分配冲突。 cnio拿到报文后,查询本机路由,匹配的是16位掩码的flannel.1,因此将报文丢给flannel.1。
[root@note2 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.181.254 0.0.0.0 UG 100 0 0 eno16780032
10.1.0.0 0.0.0.0 255.255.0.0 U 0 0 0 flannel.1
10.1.15.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.181.0 0.0.0.0 255.255.255.0 U 100 0 0 eno16780032
3、flannel.1是个什么类型的网卡呢?图示的下一跳是flanneld,一个用户态进程(当然,这个进程已经包装在docker容器里了),这是怎么实现的呢? 这里需要重提一下linux上用户态和内核态通信的手段。一般来说,有以下几种:
- netlink socket
- syscall,例如调用用户态的read/write接口
- IOCTL
- procfs,例如读取/proc目录下的ip统计计数
还有一种手段,使用TUN/TAP接口。
tun/tap驱动程序实现了虚拟网卡的功能,tun表示虚拟的是点对点设备,tap表示虚拟的是以太网设备,这两种设备针对网络包实施不同的封装。利用tun/tap驱动,可以将tcp/ip协议栈处理好的网络分包传给任何一个使用tun/tap驱动的进程,由进程重新处理后再发到物理链路中。开源项目openvpn( http://openvpn.sourceforge.net)和Vtun( http://vtun.sourceforge.net)都是利用tun/tap驱动实现的隧道封装
具体到k8s上,flanneld包装在flannel-git容器中,该容器与宿主机是同一网络namespace;flanneld启动时会创建flannel.1网卡,用来接收所有发送到10.1.0.0/16网络的报文;上面第2步报文转给flannel.1后,内核会将报文上送给flanneld。
[root@node1 ~]# docker ps
92197740eeef quay.io/coreos/flannel-git:v0.6.1-62-g6d631ba-amd64 "/opt/bin/flanneld --" 22 hours ago Up 22 hours k8s_kube-flannel.135690a3_kube-flannel-ds-ze30q_kube-system_ce4936c7-dd2c-11e6-9af1-000c29906342_1faf7ca4
4、flanneld维护了一份全局的node网络信息,根据报文目的地址查询得到该地址对应的node信息后,将报文封装到udp中(新报文的目的地址为对应node的地址),再将封装后的udp报文查询路由后经过物理网络(eno16780032)发送给目的node。
5、对端node收到报文后,走普通的查询路由为本机后上送用户态流程,封装报文交给flanneld。之后,报文解包、根据新包目的地址查路由,交给目的pod的容器。
[root@node1 ~]# netstat -anup|more
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
udp 0 0 0.0.0.0:8472 0.0.0.0:*
flannel模式:udp vs vxlan
最大的缺点是,所有报文都需要走flanneld这个用户态进程进行一次封装后,才能出去。当网络流量较大时,flanneld将会成为瓶颈;相对来说,open vswitch可能稳定性、可靠性会更好一些。 但flannel也有ovs所不具备的优点:flannel能够通过etcd感知k8s的service变动,动态维护自己的路由表(第4步)。
1.5.4版本的kubernetes,默认flannel的网络backend是用的vxlan,与udp方式最大的不同是,报文的封装、解封装,是在内核做的(vxlan module),用户态的flanneld仅仅是控制平面,数据平面的报文直接从内核封装出去,可以避免udp backend里flanneld成为瓶颈。
另,vxlan方案中,node发起对端的arp解析时,会先触发arp_solicit,将出发一个L3MISS事件到用户态的flanneld,由flanneld根据从apiserver捅过来事件生成的表项来代答,所以如果在flannel.1上抓包,看不到arp报文。
部署及验证
1、部署 flannel部署比较简单。在master上kubeadm init完成后,执行下面的命令。该yaml定义了flannel容器以及相关的配置容器。有一些材料没有使用容器部署,相对来说复杂一点。
kubectl create -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
之后查看kube-flannel的状态,Running则成功。此时k8s集群只有master一台机器,再登陆到2个node上,执行kubeadm join --token={token_id} master_ip将node加入到k8s集群中。最终在master上查看结果如下。
[root@localhost k8s]# kubectl get nodes
NAME STATUS AGE
localhost.localdomain Ready 1d
node1 Ready 23h
note2 Ready 23h
[root@localhost k8s]#
[root@localhost k8s]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
dummy-2088944543-vafe7 1/1 Running 0 1d
etcd-localhost.localdomain 1/1 Running 1 1d
kube-apiserver-localhost.localdomain 1/1 Running 1 1d
kube-controller-manager-localhost.localdomain 1/1 Running 0 1d
kube-discovery-982812725-5j9ri 1/1 Running 0 1d
kube-dns-2247936740-gqifl 3/3 Running 0 1d
kube-flannel-ds-kfcpe 2/2 Running 0 1d
kube-flannel-ds-klmfz 2/2 Running 7 23h
kube-flannel-ds-ze30q 2/2 Running 4 23h
kube-proxy-amd64-2yx0g 1/1 Running 0 1d
kube-proxy-amd64-hcj9t 1/1 Running 0 23h
kube-proxy-amd64-vhevz 1/1 Running 0 23h
kube-scheduler-localhost.localdomain 1/1 Running 1 1d
在node上,可以看到flannel.1等网卡信息。
2、验证
将下面的RC保存为alpine.yaml。
apiVersion: v1
kind: ReplicationController
metadata:
name: alpine
labels:
name: alpine
spec:
replicas: 2
selector:
name: alpine
template:
metadata:
labels:
name: alpine
spec:
containers:
- image: mritd/alpine:3.4
imagePullPolicy: Always
name: alpine
command:
- "bash"
- "-c"
- "while true;do echo test;done"
ports:
- containerPort: 8080
name: alpine
并创建namespace、apply。
kubectl create namespace alpine
kubectl apply -n alpine -f alpine.yml
等待一段时间后,在master上查看apply情况(-o wide可以看到更多信息,即IP/node):
[root@localhost k8s]# kubectl get pods -n alpine -o wide
NAME READY STATUS RESTARTS AGE IP NODE
alpine-4zmey 1/1 Running 0 23h 10.244.1.2 note2
alpine-55zej 1/1 Running 0 23h 10.244.2.2 node1
2个pod分别跑在2个node上(前面yml定义的replicas为2)。
登陆到其中一个node上,进入对应的容器docker exec -it {docker_id} bash,ping对端的ip地址看是否通。如果不通,可能你使用的也是CentOS操作系统,它的iptables默认会丢弃所有报文并回复icmp-host-prohibited,所以需要将flanneld监听的8472端口/udp协议的报文加到INPUT链上,各个物理node上都要执行。
当然,我觉得更好的做法是flannel自己来加这条规则。
[root@node1 ~]# iptables -I INPUT -p udp -m udp --dport 8472 -j ACCEPT
[root@node1 ~]#
[root@node1 ~]# iptables -L -n|more
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:8472
...
REJECT all -- 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited
在物理网卡上抓了个包,可以看到该UDP包的payload中黑色横线标记的2个ip地址。
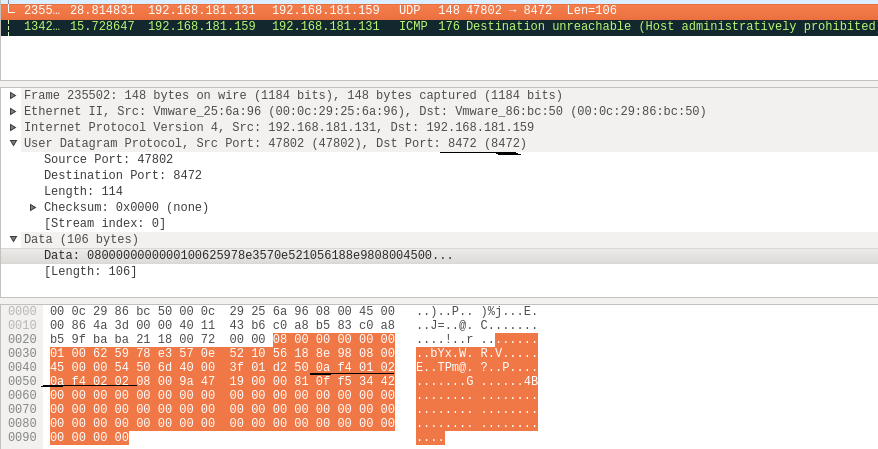
以上。
Subscribe via RSS