Spark(五):在Zeppelin中分析IPv4地址的瓜分图
by 伊布
背景介绍
Spark可以像Hadoop一样用来跑大作业,也可以像数据库一样做实时分析。对于后者,Spark的发行版中提供了spark shell、spark sql,数据科学家可以在这里面做一些分析。不过命令行的可编辑、可视化方面毕竟不友好,因此一些厂商开发了web IDE,而开源界也提供了这样的工具:Zeppelin(齐普林?)。
Zeppelin是一个Web笔记形式的交互式数据查询分析工具,除了可以对接spark进行scala、python、sql的分析外,还可以对接hive、cassandra、kylin、phoenix、elasticsearch 等等。
安装
Zeppelin的安装十分简单。我从官网下载了0.5.6的release bin包,解压。默认其监听端口是8080,但在我的机器上这个端口号已经被spark的web ui占用了,所以我改为了8888:将zeppelin-site.xml.template复制一份为zeppelin-site.xml,并修改zeppelin.server.port的value即可。
服务启动、停止:
bin/zeppelin-daemon.sh start
bin/zeppelin-daemon.sh stop
我没有把Zeppelin装到yarn上。start后,打开http://host:8888接能看到页面了。下面介绍几个概念:
- Interpreter:注释器,对应实际运行的spark集群、hive服务器等等,可以在页面上配置服务地址等参数。
- Notebook:笔记本,我理解为一系列的分析,范加尔的小本子。note可以通过%xxx来定义其对应的interpreter,例如%hive对应hive,%spark/%sql/%pyspark对应spark。
默认装好后有一个Tutorial,可以看看官方给的几个示例。我们自己create new note,下面的几个操作都在这个note里做。
对接hive
我用spark的thrift server来替代hive。首先配置Interpreter中hive的default.url(jdbc:hive2://ipaddr:port)和default.user,save后记得restart下。 下面是个简单的例子,其实跟beeline类似,但Zeppelin做的比较好的一点是它直接集成了图形化,SQL(包括spark sql)出来的数据可以转为直方图、饼图、趋势图、分布图等等。
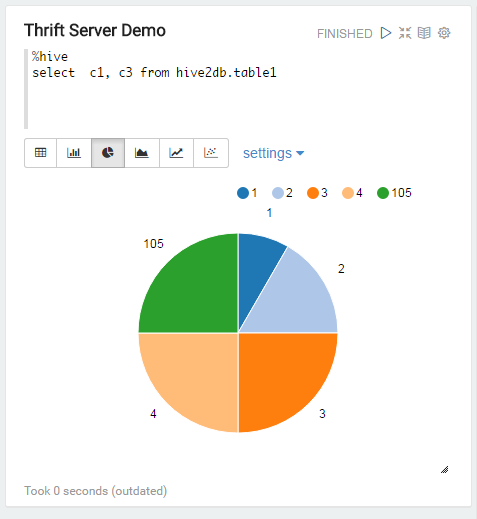
对接spark
类似hive,需要修改Interpreter中spark的master项。我这里直接提交到spark集群上:spark://spark1:7077。
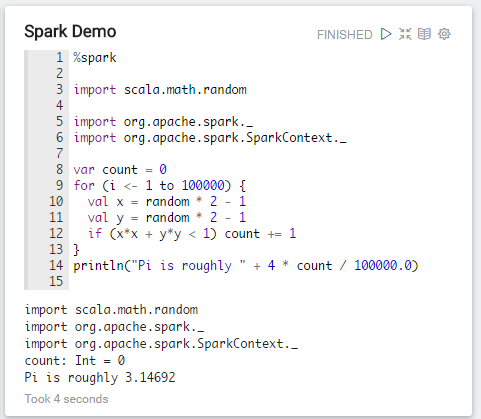
例一:求Pi值
类似spark的解释器。
例二:IP地址瓜分图
本例稍微复杂一点:我在一个note中读取hdfs上的文件并注册为临时表(%spark),然后在另一个note中使用sql分析(%sql)。Zeppelin的各个note实际共用一个spark context,用户不需要也不能自定义sc。
1、编写scala部分代码。
数据如下:
3757755392,3757834239,CN,310000,310100,-1,100023,31.0456,121.4
3757834240,3757835775,AU,AU_04,Brisbane,-1,3000683,-27.4679,153.028
3757835776,3757836031,AU,AU_04,Brisbane,-1,3000683,-27.4833,153.042
...
前面2列定义了IP段,第三列为国家缩写。我想统计的是不同的国家,其所获得的IP段数量,看看是不是美国占了最多的资源(那还用说)。
代码如下,聪明如你一看就懂。
%spark
import sqlContext.implicits._
val ip2region = sc.textFile("hdfs://spark1:8020/upload/ipdata_code_with_maxmind.txt")
case class Ip(ipstart:Long, ipend:Long, country:String, province: String, city : String, county: String)
val ip_map = ip2region.map(s=>s.split(",")).filter(s=>(s.length==9)).map(
s=>Ip(s(0).toLong,
s(1).toLong, s(2), s(3), s(4), s(5))
).toDF()
ip_map.registerTempTable("ip2region")
可以点击下执行,不过由于这里都是transform,所以实际没做啥。
插一下
由于我们是把Zeppelin直接提交到spark集群上的,所以在spark的页面上,可以看到Zeppelin的Application,这个app可以被kill掉(灰色的kill)。

点进去后可以看到一个个的作业。
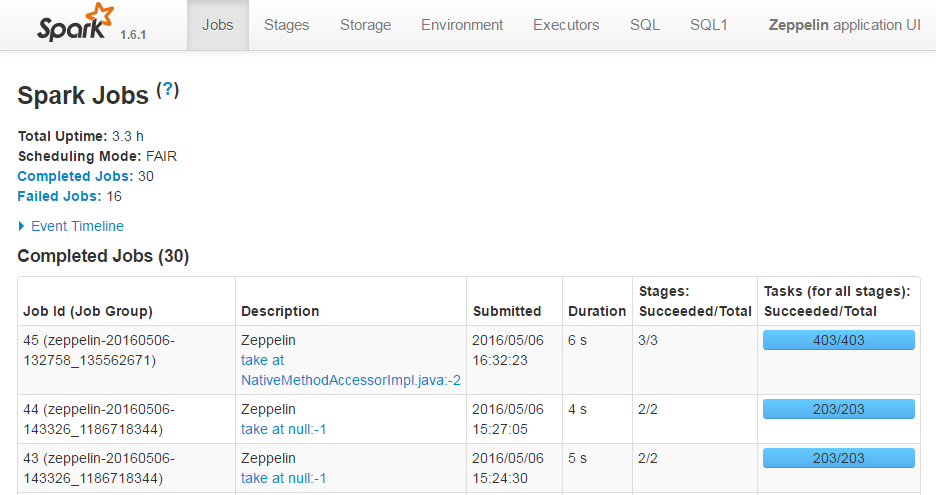
如果只是transform,不会形成作业;直到要action才会提交作业上去(图中第一行就是下面跑sql出来的)。我理解这就是spark的惰性求值的意思吧。
2、编写sql
现在已经有了一个叫ip2region的临时表,下面就可以直接对这个表进行计算了。
select distinct country, count(1) as sum from ip2region group by country order by country
不过,上面的计算比较粗糙,实际上每行记录所包含的地址段并不都是256个,有的记录是子网段的,如只有64个、128个,按行来统计的结果可能不准。 结果如下。
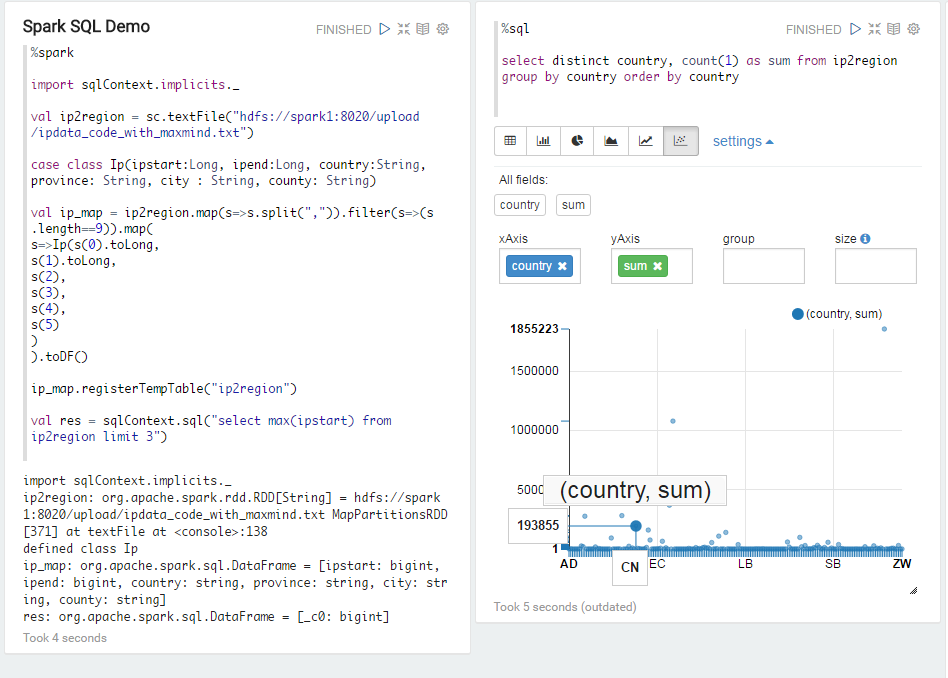
右上角的点是美国,左下高亮的点是中国。虽然我对CN分配的IP地址段会比较少做好了心理准备,但跟美国差距这么大,还是没想到的。当然总的来说我们的IP地址还是挺多的。
其他功能
- Zeppelin默认没有用户隔离,多个浏览器看到的是一样的(勉强认为具备了协同开发的能力吧)
- 可以将note保存成json串归档为文件,其他集群将该文件导入后,可以恢复note
- 可以根据note的URL来导入(how?)
- 可以定时执行note。由于定时执行时,note各部分是有执行顺序的,可以勉强认为具备了工作流的能力 XD
…
Subscribe via RSS