Spark(二):Standalone和YARN方式部署集群
by 伊布
Spark有三种集群部署方式:
- standalone
- mesos
- yarn
其中standalone方式部署最为简单,下面做一下简单的记录。后面我还补充了YARN的方式。
其实最简单的是local方式,单机。
1 环境
我在一台服务器上安装了ESXi来管理虚拟机,多个虚拟机组成spark集群。虚拟机软件配置如下:
- 安装ubuntu server 14.04版本
- 安装OpenJDK 1.7
- 用户名为ieevee,具备sudo权限,并且sudo执行命令时不需要输入密码
- master上配置所有节点的/etc/hosts记录
- 安装pssh
配置无密码sudo方法如下。
root@spark1:/etc# chmod u+w sudoers
root@spark1:/etc# echo "%ieevee ALL=(ALL) NOPASSWD: ALL" > sudoers
root@spark1:/etc# chmod u-w sudoers
我做的虚拟机镜像配置了/home/ieevee/.ssh/authorized_keys,默认打通了ssh免密登录。
2 部署
我们先部署1个master+3个slave的集群。感叹下,相比之下某阿公司的ADS产品,spark的部署真的太简单了。
我用的spark为目前的release 1.6.1 pre-build版本,官方下载for hadoop 2.6的即可。将该包丢到集群的各个机器上,解压。我解压后的路径是/home/ieevee/spark/spark-1.6.1-bin-hadoop2.6。
2.1 单独启动
启动master
到spark1机器上,执行./sbin/start-master.sh ,启动master。查看日志,可以找到如下2个路径:
- spark集群内master路径:
spark://spark1:7077,下面slave启动时需要用这个路径来指定master - WEB UI路径:
http://192.168.181.73:8080,浏览器打开可以看到里面空空如也,什么资源也没有。
启动slave
到spark2机器上,执行./sbin/start-slave.sh spark1:7077,启动第一个slave,此时在WEB UI可以看到Alive Workers为1,core、memory为该slave节点的所有资源(内存扣1G给操作系统),workers中可以看到spark2。
继续到spark3、spark4机器上执行./sbin/start-slave.sh spark1:7077,最终在WEB UI上看到的情况如下:
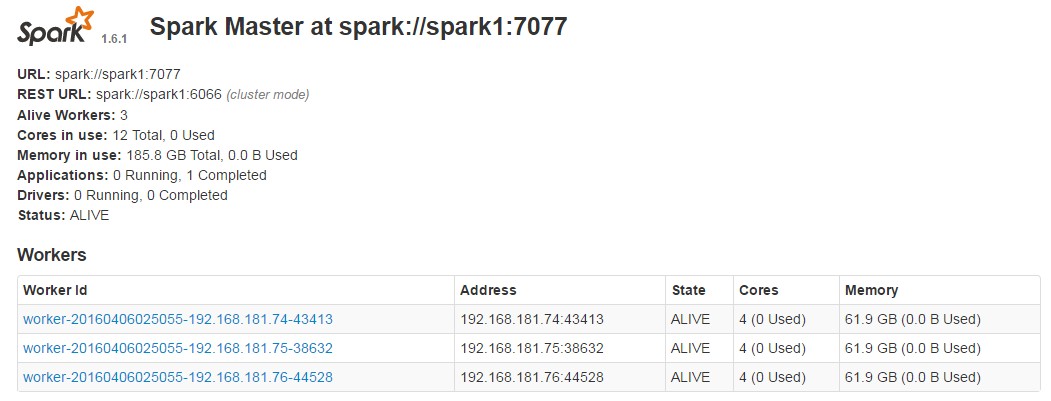
2.2 集中启动
当然上面这样做很麻烦,需要在每个节点上启动进程,更好的办法是在master(spark1)上配置slaves节点,统一启动。
在spark1上:
cp ./conf/slaves.template ./conf/slaves
echo "spark2" >> ./conf/slaves
echo "spark3" >> ./conf/slaves
echo "spark4" >> ./conf/slaves
./sbin/start-all.sh
如果后面觉得slave资源不够了,仍然可以安装2.1的做法,在新节点上./sbin/start-slave.sh spark1:7077,可以动态的加载上去,并且在master上执行stop-all.sh,也可以把新加的这个节点stop掉(这么友好我都快哭了)
2.3 验证
如上,资源已经有了,下面我们跑个简单的任务。
./bin/spark-submit --master spark://spark1:7077 --class org.apache.spark.examples.SparkLR --name SparkLR lib/spark-examples-1.6.1-hadoop2.6.0.jar
spark-submit可以指定master,我们这里因为是standalone,所以指定了spark1的路径,yarn/mesos不同。执行完毕后到WEB UI上可以看到该任务在3个slave节点上都跑了响应的作业。
还可以指定--supervise,如果应用返回非0值会做重试。
2.4 资源调度
standalone模式下,任务遵从FIFO调度。由于默认任务会使用所有资源,所以同一时刻只能跑一个任务;不过我们可以限制每个任务占用的资源,这样可以多个用户同时使用。mesos或者yarn模式会更自由一些。
3 HA
多个slave的情况下自动具备了worker的HA,因为spark会将失败的任务调度到其他worker上执行。但是,master还是有单点的,如果master故障了,那么用户就无法提交新的作业了。注意,已经提交到worker的作业不受影响。
spark官方给出了2种解决方法,一个是使用zk做分布式协调,zk选主;另一个是使用基于LOCAL FILE SYSTEM恢复的单节点方案。第二种其实只有1个master实例,当master故障后服务不可用,必须重启master进程,一般在生成系统上是不可接受的,所以我采用的是第一种方式。
我在spark1的基础上,增加了2台master:spark11和spark12.
3.1 配置ZK
ZK也需要部署为集群模式,分别装在spark1/spark11/spark12,三台机器都要执行下面:
cp conf/zoo_sample.cfg conf/zoo.cfg
echo "server.1=spark1:2888:3888" >> conf/zoo.cfg
echo "server.2=spark11:2888:3888" >> conf/zoo.cfg
echo "server.3=spark12:2888:3888" >> conf/zoo.cfg
touch data/myid
# 下面的“1”,在不同的机器上替换为对应的值。
echo "1" > /data/myid
./bin/zkServer.sh start
启动后,我们任意选择一个机器上的./bin/zkCli.sh连上去,确保zk好用:
./bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0] connect spark1:2181,spark11:2181,spark12:2181
[zk: spark1:2181,spark11:2181,spark12:2181(CONNECTED) 1] ls /
[zookeeper]
3.2 配置master
为了使能recovery mode,需要在start-env.sh中指定SPARK_DAEMON_JAVA_OPTS,具体为以下三个参数:
| 参数 | 意义 |
|---|---|
| spark.deploy.recoveryMode | 需要配置为ZOOKEEPER,默认是NONE |
| spark.deploy.zookeeper.url | ZK url,如”spark1:2181,spark11:2181,spark12:2181” |
| spark.deploy.zookeeper.dir | zk上的路径,默认为’spark’ |
我修改了前面2个参数。
cp conf/spark-env.sh.template conf/spark-env.sh
echo "SPARK_DAEMON_JAVA_OPTS=\"$SPARK_DAEMON_JAVA_OPTS -Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=spark1:2181,spark11:2181,spark12:2181\"" >> conf/spark-env.sh
3.3 检验HA
我没找到好的集中启动的方式,采用的还是每个机器上单独命令启动的方式,简单起见,测试的时候我启动了3台master和1台slave(spark2机器)。
master的启动跟之前是一样的,slave有不同:
./bin/start-slave.sh spark1:7077,spark11:7077,spark12:7077
简要说明下。3台master启动后,在WEB UI上能看到其状态,我这里的情况是2台ALIVE(例如spark1和spark11),1台STANDBY(spark12);spark2启动后,只有1台master上(例如spark11)可以看到其计算资源,其他2台看不到;将spark11关闭,过一两分钟后可以看到spark1上拿到了计算资源,查看spark2的日志,能看到重连的过程。
实际上,spark的master HA机制做的非常优秀的一点是,master的切换是由新master来通知之前注册过的slaves的。因此,standby master并不要求一开始就部署上去,slave启动的时候,也不需要像上面这样指定3个spark url。 上面的过程可以做个小优化,即仍然在spark1上start-all,然后再将spark11/spark12加入到集群的master中。这样即使spark1故障关闭了,新的master仍然可以接管计算资源。
不过美中不足的是,集群切换的时间有点长,官方说法是1-2分钟,不知道是不是跟故障发现的频率太低有关系。
4 Spark on YARN
我理解现在的spark on yarn 也只是说spark的任务跑在yarn上,这样区别于standalone方式,可以有一个公共的资源管理模块来提供服务。
配置YARN略去不谈,可以参考这篇文章。
YARN配置好后,还需要设置环境变量来指定HADDOP/YARN的配置文件,SPARK启动的时候会去这个目录中找YARN的配置文件,用来向YARN提交任务。
export YARN_CONF_DIR=/home/ieevee/hadoop/hadoop-2.6.3/etc/hadoop
export HADOOP_CONF_DIR=/home/ieevee/hadoop/hadoop-2.6.3/etc/hadoop
启动SPARK任务的命令行,指定的–master与以前不一样,例如启动thriftserver:
./sbin/start-thriftserver.sh --master yarn
这样就可以在YARN上有一个常驻的JDBC server,使用beeline就可以开心的连上去做SQL操作了。
Subscribe via RSS