Greenplum上手报告
by 伊布
搬运工又上班了!
简介
Greenplum应用在OLAP领域,MPP架构,其底层使用Postgre,支持横向扩展,支持行存储、列存储,支持事务、ACID。
MPP数据库主打share nothing,即各节点间任何资源都不共享,从硬件的CPU/内存/网络/存储,到上层的操作系统,各节点都是独立的;节点间的交互主要通过网络进行通信。由于数据量越来越大,OLAP产品多采用MPP架构,例如阿里的ADS,百度的Palo。 相对于MPP,也有Oracle RAC这种share everything架构,各节点共享存储、内存客户互相访问。SMP由于只能使用一个节点,容易受到具体硬件的限制,但支持事务的效率比较高(不需要跨节点通信);MPP扩展性好,更适应big data的场景,但多数MPP数据库不支持事务、ACID(例如阿里云ADS)。MPP数据库需要仔细设计数据的存储,避免出现大量的节点间shuffle通信,否则效率极低。
关于GP的架构分析,可以参考这篇文章。
Greenplum在2015年已经开源,Apache 2.0协议,源码可以访问Github。GP使用C语言,据说其代码非常漂亮。不过Greenplum的开源并不彻底,没有包含其新一代优化器orca(核心资产,咳咳)。不过从一些测试结果来看,开源版本与商业版本的性能差别不大,后面我们可能看到很多基于Greenplum包装的OLAP产品。
GP的架构是典型的Master-Segments,主控节点和计算节点分离,类似HDFS。
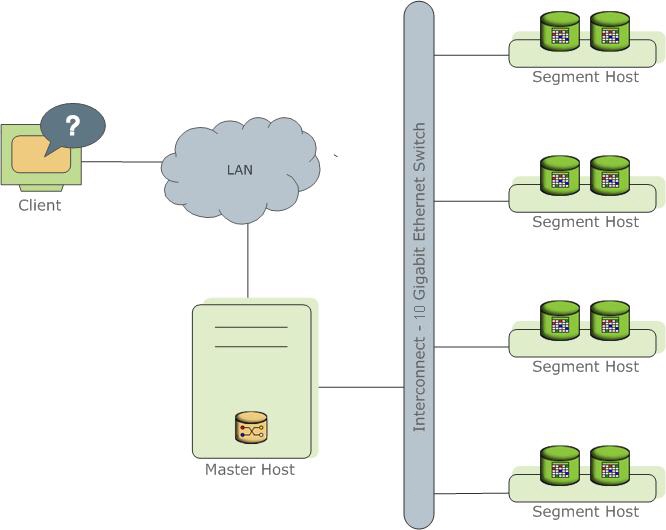
Master中只提供接入服务和元数据存储,用户实际数据存储在Segments中。GP使用UDP通信,但在UDP之上做了确认机制。没有使用TCP的原因是,TCP会限制最多1000个Segments(为什么呢?)。但从阿里实际使用的情况来看,UDP并不稳定,他们还是改用了TCP。
- 创建表时,需要指定distributed by(类似ADS的分区列,可以指定单列或多列,据此判断数据分布到哪个Segment)。如果不指定则使用第一列(吐槽下这个特性,建表这种频率很低的事情不应该以方便为主,而应该强制要求,避免用户不熟悉出错)。
create table faa.d_airports (airport_code text, airport_desc text) distributed by (airport_code);
- 插入时,根据规则(如hash),不同主键的数据分配到不同的Segment存储。GP的hash算法可以做到数据基本均匀分布到各个Segment。GP也可以配置为数据随机分布到各个Segment。
- 查询时,由Master根据当前的Segments情况生成SQL执行计划,交给各个Segment执行;Master汇总各Segment执行结果,并返回给client
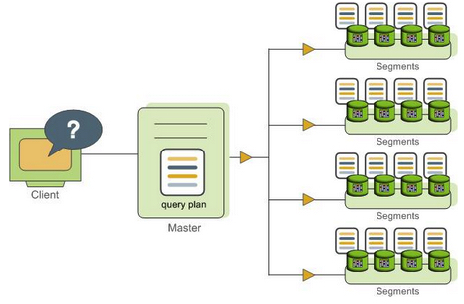
但是GP的查询会发生shuffle。
- 数据装载时,使用gpfdist直接从外部数据源并行拖到Segments上,并且各Segments下载时并不是只下载自己的数据,而是先下载,发现不是自己的数据,再丢给正确的Segment。并行装载号称1小时2TB。
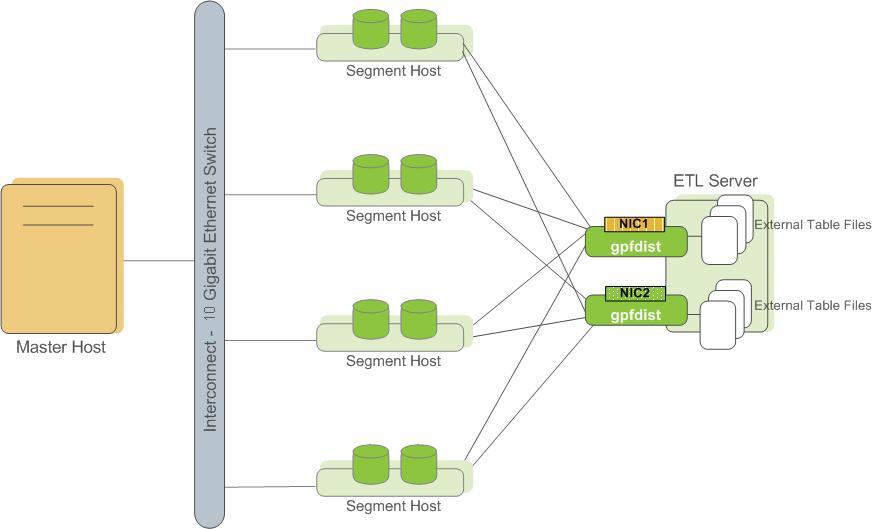
Segment支持横向扩展。
安装
Greenplum在其官方网站提供了用于RHEL(CentOS)、SuSE的版本。
我的环境使用了3台虚拟机:1M+2S,虚拟机安装CentOS6.5,安装步骤参考这篇文章,非常详细。不过我这出过一个错误,免密码打通的时候,root没成功,后面手工配置的(比较奇怪,必须使用下面的命令来copy公钥,不能拷贝方式)。
ssh-copy-id -i .ssh/id_rsa.pub root@your_remote_host
HA
GP支持为Master和Segment配置Mirror以提供高可靠性。
-
Master->Mirror:使用postgre的日志同步功能。可以在部署时配置,也可以在Master运行时配置。

-
Segment->Mirror:如下图,一个Segment host可以配置多个Segment instance;以一个DB为例,配置mirror后,某一Segment instance会在另一Segment host上提供mirror instance。

相比GP,ADS的计算节点(类比Segment)可以2个实例同时工作,一定程度上可以提高查询性能。ADS管控节点(类比Master)也是单独的实例(主备),但以进程的形式存在,并不需要同步。GP的HA设计的不算太好,以Segment为例,默认HA策略是切换为Read-only,即只能读不能写;如果HA策略是continue,仍然可以读写,但当故障节点恢复后,最终需要重启GP集群。(能忍?)
更多详细HA信息,移步到GP官网。
使用
安装完毕后,用户可以使用Postgre SQL的客户端来访问Greenplum;一些BI系统可以直接对接。
特性
1. Append only table
2. column oriented table(列存表)
3. Append only table可以压缩
CREATE TABLE bar (a int, b text)
WITH (appendonly=true, orientation=column) DISTRIBUTED BY (a);
CREATE TABLE foo (a int, b text)
WITH (appendonly=true, compresstype=zlib, compresslevel=5);
4. 分区表(partition)
可以指定某一列的按range分区。如下例,表中2008年的数据都会根据date每天建立一个分区。
CREATE TABLE sales (id int, date date, amt decimal(10,2))
DISTRIBUTED BY (id)
PARTITION BY RANGE (date)
( START (date '2008-01-01') INCLUSIVE END (date '2009-01-01') EXCLUSIVE EVERY (INTERVAL '1 day') );
这一点ADS与GP不同。以ADS为例,其一级分区与GP是类似的,是按照分区列hash到不同的节点;而二级分区不同,ADS实际是一种“指定”,上传一批数据时,额外指定其时间属性,该列并不在上传数据中。 GP的分区表应该能提高查询性能,例如查询时where条件为between..and,由于已经建立了分区,大部分数据可以迅速索引到。而ADS是自行建立了列索引,不需要用户干预。
5. 数据可以重分布
若前期由于数据分区不合适造成数据倾斜,还可以重分布,其实就是数据搬移。但重分布代价较高,尽量在设计表时就确定好分区列。
查询详解
GP会将查询分为一个一个的slice,并分配到各个segment执行。 举个例子。
先创建测试表及测试数据。GP/Pg支持直接生成测试数据,不得不说这个功能实在是太暖心了,特别是在POC的时候。
create table t1(id int primary key,cn int,name varchar(40)) distributed by (id);
create table t2(id int primary key,cn int,name varchar(40)) distributed by (id) ;
create table t3(id int primary key,cn int,name varchar(40)) distributed by (id) ;
insert into t1 select generate_series(1,1000000),generate_series(1,1000000),generate_series (1,1000000);
insert into t2 select generate_series(1,1000000),generate_series(1,1000000),generate_series (1,1000000);
insert into t3 select generate_series(1,100),generate_series(1,100),generate_series(1,100);
GP在scan、group by等基础上,增加了motion。motion是指查询过程中涉及其他segment的数据在各个节点间移动。主要有三种:
- Broadcast Motion(N:N),即广播数据,每个节点向其他节点广播需要发送的数据。
- Redistribute Motion(N:N),重新分布数据,利用join的列值hash不同,将筛选后的数据在其他segment重新分布。
- Gather Motion(N:1),聚合汇总数据,每个节点将join后的数据发到一个单节点上,通常是发到主节点master。
1. 最简单的全表scan、聚合、motion。
postgres=# explain select count(*) from t1;
Aggregate (cost=13863.86..13863.87 rows=1 width=8)
-> Gather Motion 2:1 (slice1; segments: 2) (cost=13863.80..13863.84 rows=1 width=8)
-> Aggregate (cost=13863.80..13863.81 rows=1 width=8)
-> Seq Scan on t1 (cost=0.00..11360.24 rows=500712 width=0)
Optimizer status: legacy query optimizer
postgres=# select count(*) from t1;
1000000
说明:
- cost只该操作返回第一行的时间,比如seq scan的cost总是0,但Aggregate集约函数的cost较大,因为得先合并。
- rows为该操作影响到的行数。由于我的环境有2个segment,所以差不多一个是50W左右
- 倒着往上看(废话)
本例中最终所有结果汇总到了master。
2. 根据分区列做聚合
如下,id即为表t1的分区列,数据进GP的时候就已经按照id分配到了不同的segment,所以聚合时只要各个segment简单相加即可。
postgres=# explain select id,count(*) from t1 group by id;
QUERY PLAN
-------------------------------------------------------------------------------------------
Gather Motion 2:1 (slice1; segments: 2) (cost=19447.91..35046.26 rows=1001424 width=12)
-> HashAggregate (cost=19447.91..35046.26 rows=500712 width=12)
Group By: id
-> Seq Scan on t1 (cost=0.00..11360.24 rows=500712 width=4)
Optimizer status: legacy query optimizer
(5 rows)
3. 非分区列做聚合
postgres=# explain select name,count(*) from t1 group by name;
Gather Motion 2:1 (slice2; segments: 2) (cost=69888.29..88359.38 rows=1001424 width=106)
-> HashAggregate (cost=69888.29..88359.38 rows=500712 width=106)
Group By: t1.name
-> Redistribute Motion 2:2 (slice1; segments: 2) (cost=16367.36..48913.64 rows=500712 width=106)
Hash Key: t1.name
-> HashAggregate (cost=16367.36..28885.16 rows=500712 width=106)
Group By: t1.name
-> Seq Scan on t1 (cost=0.00..11360.24 rows=500712 width=6)
Optimizer status: legacy query optimizer
name不是分区列,因此需要各segment处理完本地数据后,再根据name做hash distribution,重分布。
4. 大小表
postgres=# explain select t1.id,t1.name,t3.name from t1,t3 where t1.cn=t3.cn;
QUERY PLAN
---------------------------------------------------------------------------------------------------
Gather Motion 2:1 (slice2; segments: 2) (cost=8.50..13873.80 rows=101 width=12)
-> Hash Join (cost=8.50..13873.80 rows=51 width=12)
Hash Cond: t1.cn = t3.cn
-> Seq Scan on t1 (cost=0.00..11360.24 rows=500712 width=14)
-> Hash (cost=6.00..6.00 rows=100 width=6)
-> Broadcast Motion 2:2 (slice1; segments: 2) (cost=0.00..6.00 rows=100 width=6)
-> Seq Scan on t3 (cost=0.00..3.00 rows=50 width=6)
Optimizer status: legacy query optimizer
(8 rows)
GP选择将t2全表扫描后,广播给所有节点,然后在各节点上做hash join(就是where ..)。相比之下ADS的做法更聪明(当然也更粗暴),为了避免大量的网络通信(小表也是表啊),ADS将此类小表定义为维度表,每个物理节点一份,这样做join的时候直接读取即可,连broadcast都不需要。
Subscribe via RSS