如何使用kettle提高ADS插入速度
by 伊布
背景介绍
我们需要从kettle将数据导入到ADS,但导入性能不理想,32并发线程,单个ADS接入节点,也只有最多六七千条每秒的样子。
从kettle日志来分析,其抽取机制是每个线程先从源端读取5W条,然后再向目的端写入5W条。
2015/12/15 10:38:30 - step1.0 - linenr 900000
2015/12/15 10:38:54 - step2.0 - linenr 900000
2015/12/15 10:40:27 - step1.0 - linenr 950000
2015/12/15 10:40:52 - step2.0 - linenr 950000
默认kettle的插入是一条insert语句插入一条记录。这样会有2个影响
- 从网络通信角度来看,报文的负载较高,传输效率低,并且大量的时间浪费在了报文收发上
- 数据端需要对每条insert都需要单独处理,如事务、存储、加解锁等
解决方法
既然单条insert效率不高,那么一条insert语句插入多条记录(batch insert)就可以解决这个问题。具体举例如下: batch insert之前,在服务器端看到的插入是这样的:
INSERT INTO t (c1,c2) VALUES ('One',1);
INSERT INTO t (c1,c2) VALUES ('Two',2);
INSERT INTO t (c1,c2) VALUES ('Three',3);
batch insert以后,在服务器端看到的插入是这样的:
INSERT INTO t (c1,c2) VALUES ('One',1),('Two',2),('Three',3);
服务器端
需要支持批量insert,所幸ADS支持这样的语法。
客户端
一开始我们认为需要在kettle里面增量开发代码,自己来拼装insert语句(涉世未深啊),但实际上MySQL的JDBC驱动(高于5.1.13)已经支持这样的功能了:开启rewriteBatchedStatements=true,JDBC会自动将应用丢给JDBC驱动的单条insert进行拼装。
具体来说,连接刚建立的时候,JDBC会向服务器发送show variables like max_allowed_packet来获取服务器允许的最大拼装长度,之后拼装batch insert语句时会按这个长度来。
所以只要kettle在建立跟ADS的连接时,带上rewriteBatchedStatements=true参数即可。
JDBC支持batch insert源码分析
todo
设置方式
kettle支持对数据源设置变量,这里直接贴图:
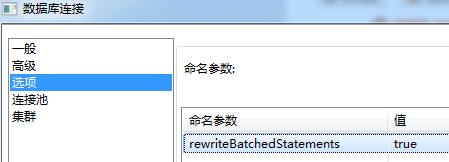
kettle支持batch insert源码分析 这块代码比较简单,记在这里以备查阅。
DataBaseMeta.java
@Override
public String environmentSubstitute( String aString ) {
return variables.environmentSubstitute( aString );
}
public String getURL( String partitionId ) throws KettleDatabaseException {
...
//先获取JDBC URL
baseUrl = databaseInterface.getURL( hostname, port, databaseName );
//再添加环境变量
StringBuffer url = new StringBuffer( environmentSubstitute( baseUrl ) );
MySQLDataBaseMeta.java
@Override
public String getURL( String hostname, String port, String databaseName ) {
if ( getAccessType() == DatabaseMeta.TYPE_ACCESS_ODBC ) {
return "jdbc:odbc:" + databaseName;
} else {
if ( Const.isEmpty( port ) ) {
return "jdbc:mysql://" + hostname + "/" + databaseName;
} else {
return "jdbc:mysql://" + hostname + ":" + port + "/" + databaseName;
}
}
}
调用Variables.java
@Override
public String environmentSubstitute( String aString ) {
if ( aString == null || aString.length() == 0 ) {
return aString;
}
return StringUtil.environmentSubstitute( aString, properties );
}
最终在StringUtil.java中根据用户设置下来的systemProperties(包含rewriteBatchedStatements)填写JDBC变量。
public static final synchronized String environmentSubstitute( String aString,
Map<String, String> systemProperties ) {
Map<String, String> sysMap = new HashMap<String, String>();
synchronized ( sysMap ) {
sysMap.putAll( Collections.synchronizedMap( systemProperties ) );
...
return aString;
}
}
Subscribe via RSS