百度PALO技术整理分析
by 伊布
以下内容基本源于百度PALO(OLAP分析引擎)对外的一个视频演讲,讲的比较形象,下面做了简单的摘抄。
总体架构图
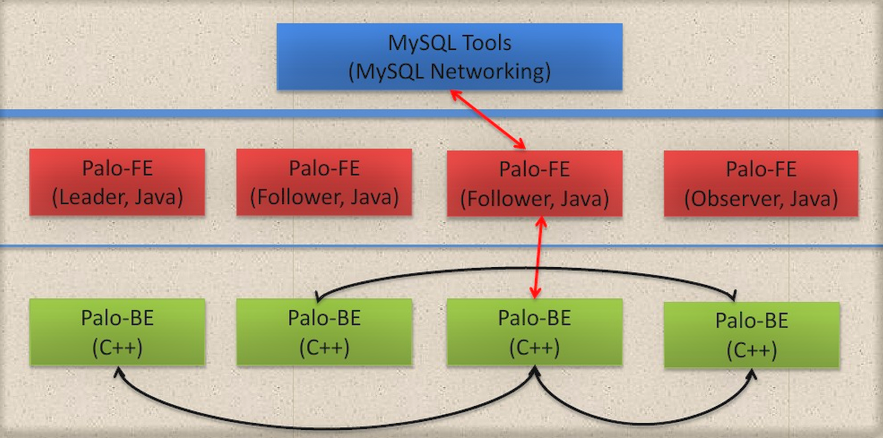
PALO对外体现为一个mysql的服务器,所有mysql相关的工具:mysql client,JDBC,基于mysql的报表工具、R语言等,都可以直接对接PALO。 FE即Front End,PALO使用了RAFT协议来共享元数据,所有FE都可以接收用户请求。RAFT协议类似PAXOS(代表实现zookeeper),但要简化很多。master故障后,follower可以根据checkpoint进行LOG回放,快速恢复元数据(内存数据库)。RAFT支持较好的横向扩展,observer就是这个作用。
数据存储
hash partition 指定表按某一列做hash分区。 elastic range partition 与hash的散列分布不同,range partition是将数据连续的分区。如何解决列的value范围无法预测的问题呢?开始的时候只有一个分区列,当数据量增长到某一临界点时,将数据平均的分成两份。后面继续类似的处理。这样数据可以比较均衡的分散到不同的分区中。range partition对where友好。
动态rollup表
发现如果用户经常只观察该表的某几个维度,则动态生成rollup表,新表里的维度表只有常用列,由于会有一定的合并,后续查找该表的速度会比较快
Compation
小批量插入的数据,文件越来越多,会导致查询性能越来越差。可以设置一个规则,每隔一段时间将一定批量的数据合并在一起,查询的数据块变少,并且索引更准确,可以提高性能
行列存
每块数据包含256行,快内列式存储,按块压缩。数据压缩比率不高,对于分析型的数据库来说,每次查询都要遍历所有数据库,效率低。 稀疏索引:数据的共同特征作为索引常驻内存(每个块对应一个索引),查询时先查索引,找到数据块以后再做解压缩。
列式存储
参考HBASE。带来的优势:
1、分析型数据库通常只涉及某些列,可以避免遍历所有数据,减少CPU/IO消耗。PALO采用的是列式存储。
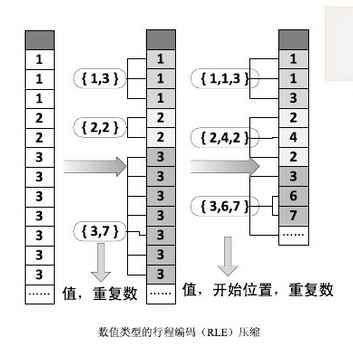 2、存储:列的数据类型一致,压缩效率高
2、存储:列的数据类型一致,压缩效率高
 3、智能索引:PALO会为每一个数据库都生成min max sum,在where sum等计算的时候,可以大幅度提高性能。
4、复合分区
3、智能索引:PALO会为每一个数据库都生成min max sum,在where sum等计算的时候,可以大幅度提高性能。
4、复合分区

库内分析
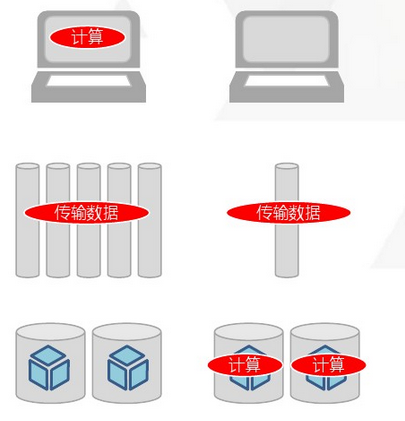 区别于数据与计算分离,可以解决网络和前端分析机器 性能的瓶颈。要求数据库有计算能力。
方法:数据库提供UDF/UDAF/UDTF。
区别于数据与计算分离,可以解决网络和前端分析机器 性能的瓶颈。要求数据库有计算能力。
方法:数据库提供UDF/UDAF/UDTF。
向量执行引擎
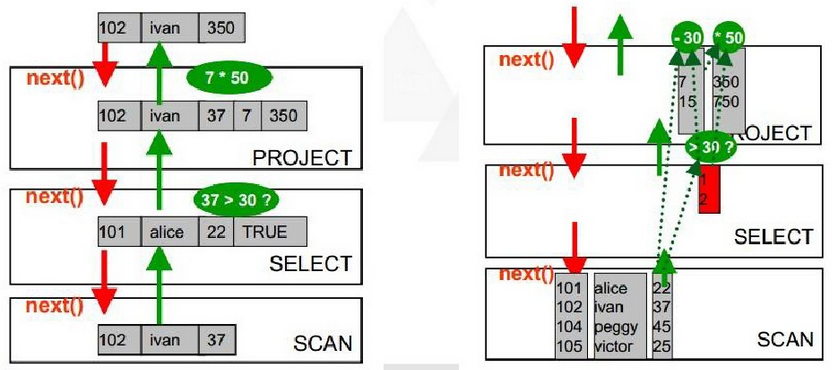 区别于遍历所有行、过滤、计算的模型,向量执行引擎可以将待计算的该列单独拿出来计算。带来的好处:
行式处理变为列式处理,避免了指令和数据的cache miss;
编译器友好,可以循环展开+分支预测
区别于遍历所有行、过滤、计算的模型,向量执行引擎可以将待计算的该列单独拿出来计算。带来的好处:
行式处理变为列式处理,避免了指令和数据的cache miss;
编译器友好,可以循环展开+分支预测
数据导入
PALO依赖于hadoop,数据必须得先上HDFS,然后分布式的将各个节点上的数据块导入到PALO,导入性能较好。 PALO不支持直接实时插入。
小批量更新、批量原子提交
其他
- 分布式管理框架,故障快速切换、恢复
- 查询引擎:share-noting MPP,可扩展好
- 大表分布式join: shuffle,即先hash partition,再做join,join数据量小,适合大量数据与大量数据之间join; broadcast,适合大量数据与小批量数据之间join,小批量数据直接与大批量数据的所有分片做join
- 谓词下推 实际就是尽早的将where条件下沉到数据库(离数据源越近越好),通过索引可以提早过滤掉数据,减少分析的数据量
Subscribe via RSS