读书笔记:hive简介(一)
by 伊布
Hive是一个运行在hadoop之上的数据仓库(dataware),目的是为精通SQL但不熟悉java的分析师提供一个在hadoop平台上数据分析的工具。 Hive提供类似SQL的接口,但并不完全相同:Hive没有完全实现SQL的所有语法,但又结合MR任务提供了一些新的方法。分析师按照HQL的语法提交任务,Hive将HQL语句翻译为MR作业。
1 安装
跟以前一样,我是用Cloudera Manager工具安装的hive。CM可以很方便删除、添加某一服务,安装时可以选择服务运行在哪一台具体设备上。CM界面虽然比ambari丑了一点,但是功能强大很多。需要注意impala/hue/oozie都依赖hive。 我安装了这几个服务:
- Hive Metastore Server,元数据服务器。配置时需要指定元数据使用的数据库是什么,我这里指定了psql。
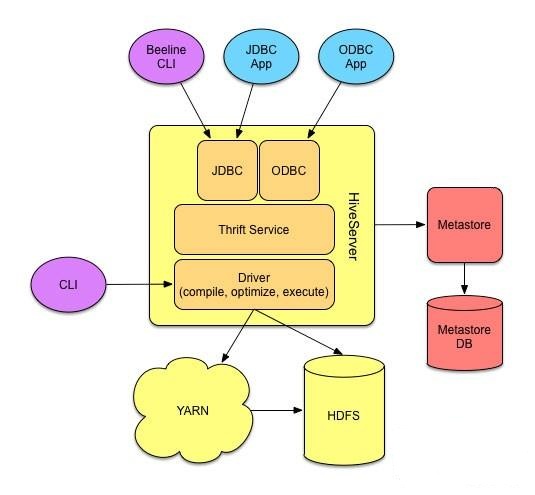
- HiveServer2,thrift服务器,通过JDBC/ODBC可以提供命令行之外的编程接口,如使用java、python等。
- WebHCat Server,Hcatalog的REST API服务器。
1.1 hive外壳环境
外壳环境是一个交互式的、通过HiveQL与hive交互的工具。hive官方推荐使用beeline(参加上面图,beeline是JDBC上的工具)作为交互式工具,由于还不太熟悉,下面我们还是以CLI(hive命令)为shell。
$ hive
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive> show databases;
OK
default
Time taken: 1.512 seconds, Fetched: 1 row(s)
hive外壳环境有如下三种使用方法:
- 可以直接在shell中使用hiveQL进行交互式的数据库操作。
- 可以执行脚本:创建一个文件hive.q,将HQL语句写到hive.q中,然后通过
hive -f hive.q执行该文件。 - 可以执行内嵌语句:
hive -e 'show tables;'
1.2 示例
下面我们用网上开房数据作为示例,演示下hive是怎么操作的(此处较水)。 a 创建一个表record2
hive> create table records2(name STRING, cardno INT, descri STRING, ctftp STRING, ctfid STRING, gender STRING, birth INT)
> row format delimited
> fields terminated by ',';
OK
解释两点:
第一点,该数据一共有30+的column,但实际我们可能并不想分析这么多,hive支持创建一个只有前面几列的表。
第二点是后面两行。这个数据是csv格式,实际就是文本格式(如下),创建表的时候我们需要指定数据格式:行记录之间用换行区分(即row format delimited),每一行内各段用逗号区分(即fields terminated by ',')。
$ head 5000.csv
Name,CardNo,Descriot,CtfTp,CtfId,Gender,Birthday,Address,Zip,Dirty,District1,District2,District3,District4,District5,District6,FirstNm,LastNm,Duty,Mobile,Tel,Fax,EMail,Nation,Taste,Education,Company,CTel,CAddress,CZip,Family,Version,id
...
b 将本地文件上传加载到hive
实际上这里只是文件的复制,将5000.csv复制到了hdfs的/user/hive/warehouse/records2/目录中去(所以hive是个数据仓库)。
指定overwrite可以覆盖原来的table。
hive> load data local inpath '5000.csv'
> overwrite into table records2;
Loading data to table default.records2
c 查询 我们查一下去开房的年龄最小的是多大。
hive> select MAX(birth) from records2 where (birth >10000000 AND birth < 20000000);
2015-05-18 05:24:16,328 Stage-1 map = 0%, reduce = 0%
2015-05-18 05:24:23,631 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.84 sec
2015-05-18 05:24:28,765 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.03 sec
MapReduce Total cumulative CPU time: 3 seconds 30 msec
Ended Job = job_1431517711165_0014
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.03 sec HDFS Read: 7495191 HDFS Write: 9 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 30 msec
OK
20130101
查到年龄最小的是2013年出生的小baby,名字叫做123。虽然我在查找的时候已经考虑到了有些数据统计不准确,把出生日期做了限制,但还是查出来一条不太有用的数据。不知道这是不是就是需要“数据清洗”了?
2 hive运行解析
2.1 配置
配置属性按照下面的的顺序优先级依次递减:
- hive shell中SET命令。配置项的值查看也是用SET,只是不要带参数。
hive> set hive.metastore.warehouse.dir;
hive.metastore.warehouse.dir=/user/hive/warehouse
- hive命令行中
-hiveconf configfile - hive-site.xml
2.2 日志
hive使用log4j。
2.3 hive服务端
- cli:也就是我们hive进去的交互式命令行接口。
- hive server 2:thrift服务器。
- metastore server:元数据服务器。
- hive web interface:使用web接口代替命令行。我这里没有安装。
2.4 客户端
thrift客户端:支持在C++/python/ruby/PHP/java等语言中嵌入hive命令。 JDBC驱动:提供给java应用程序访问hive的方法。 ODBC驱动:ODBC程序通过ODBC驱动访问hive。
2.5 metastore
metastore存放hive的元数据,主要做两件事:服务,数据存储。metastore有如下几种方式:
- 与hive服务在同一进程,使用内嵌数据库(如derby)。问题是对于一个metastore来说只能有一个hive会话,只能单用户。
- 与hive服务在同一进程,但使用独立数据库(如mysql、psql、oracle)。可以支持多用户(多会话),但有耦合。
- metastore作为一个独立的进程,可以部署在其他机器上;使用独立数据库。CM部署就是采用了这种模式。另外如果要用impala,不能使用derby。
3 与传统数据库比较
hive底层依赖HDFS,导致与传统数据库有不同。
3.1 读时模式 vs 写时模式
传统数据库采用的是写时模式,即数据写入数据库的时候,就会检查其是否符合数据库的模式(例如数据库定义本列为INT,传入STRING会报错)。 hive采用的是读时模式。数据写入数据库的时候并不检查模式是否合法,直到查询的时候才会检查。
各有各的优势与应用场景。
传统数据库的写时模式可以提高查询性能,写入时也可以做压缩;但欠缺灵活,有时数据库写入时不能确定使用什么模式。
hive的读时模式有两个优势:一是在写入数据库的时候速度很快,因为只是文件复制,不需要解析数据;二是更灵活,对于同一份数据可以支持多个模式。hive支持外部表,即数据与表分离,一份数据可以创建多个外部表,表删除时drop table xxx数据不会删除,删除的只是元数据。
3.2 更新、事务和索引
《权威指南》里指出hive因为强调为整个数据的处理,所以并没有更新这种需求。但实际还是需要追加、索引这些功能的,应该还是会逐渐补充进来的。
update: @史进: hive 0.7之后有了索引功能,0.14之后有了插入功能。
另外,通过将hive和hbase集成后,可以获得传统数据库的这些特性,详细可以查看这里。CSDN上有一篇文章,详细写了整合以后的效果,可以参考。
4 HiveQL
hiveQL是SQL的一种方言,并没有完整的支持SQL-92的所有特性,其目标更多的还是为了实际使用。但由于基于MR,hive还提供了SQL-92之外的特性,例如多表插入和transform、map、reduce等子句。
hiveQL支持两类数据类型:
- 原子数据类型:
TINYINT,SMALLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE,STRING,BINARY,TIMESTAMP,DECIMAL,CHAR,VARCHAR,DATE。原子数据类型支持隐性类型转换,其原则为往表达范围更大的方向转换;也可以使用CAST子句显式转换,如
CAST '1' AS INT将字符1转换为整型的1。 - 复杂类型:ARRAY,MAP,STRUCT,UNION
有关各类型的详细信息请参考hive wiki
挖坑不止, 未完待续
参考: 51cto:Hive已为Hadoop带来实时查询机制 《hadoop权威指南》
Subscribe via RSS